

Das Spannungsfeld von Machine Learning über AI bis hin zur Automated AI
Artificial Intelligence ist eng mit maschinellem Lernen verbunden. Maschinelles Lernen stellt Algorithmusbibliotheken bereit, die im Rahmen von AI, Anwendung finden können. Dabei nutzt die AI zusätzlich Wissenskomponenten, um auf deren Basis Entscheidungsunterstützung geben zu können. Dieses Wissen wird durch Lernen im Zeitverlauf entsprechend weiterentwickelt.
1. Der Prozess des Machine Learning
Der Prozess der Artificial Intelligence orientiert sich zunächst am Ablauf des Cross-Industry-Standard-Process-for-Data-Mining (CRISP-DM), der sich im Kontext des maschinellen Lernens etabliert hat [hierzu und zum Folgenden: Felden 2019].
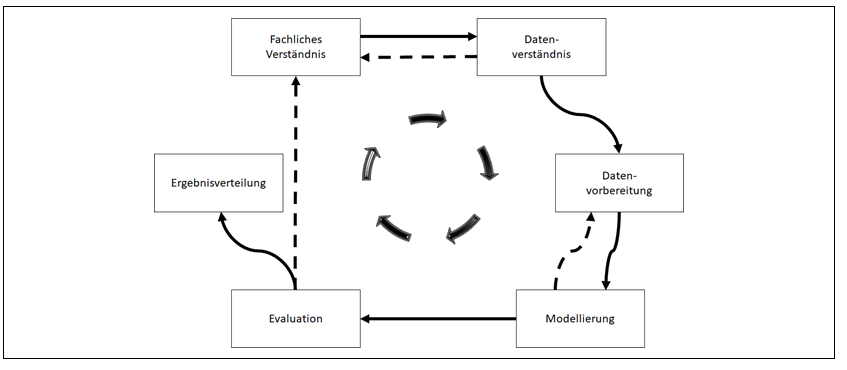
Abb. 1: Prozessschritte analytischer Ansätze
Das fachliche Verständnis bestimmt die Auswahl der Daten, wobei oftmals Rückfrag…