Im Open-Source-Umfeld ist es eine Selbstverständlichkeit, dass Beiträge in Form eines Pull-Requests vorgeschlagen werden. Und es ist auch üblich, dass diese Änderungsvorschläge – egal ob Bugfix, ein neues Feature oder eine Verbesserung der Dokumentation – von mindestens einer zweiten Person angeschaut werden, bevor sie in den Hauptbranch des Open-Source-Projekts übernommen werden.
Wie laufen Code-Reviews ab?
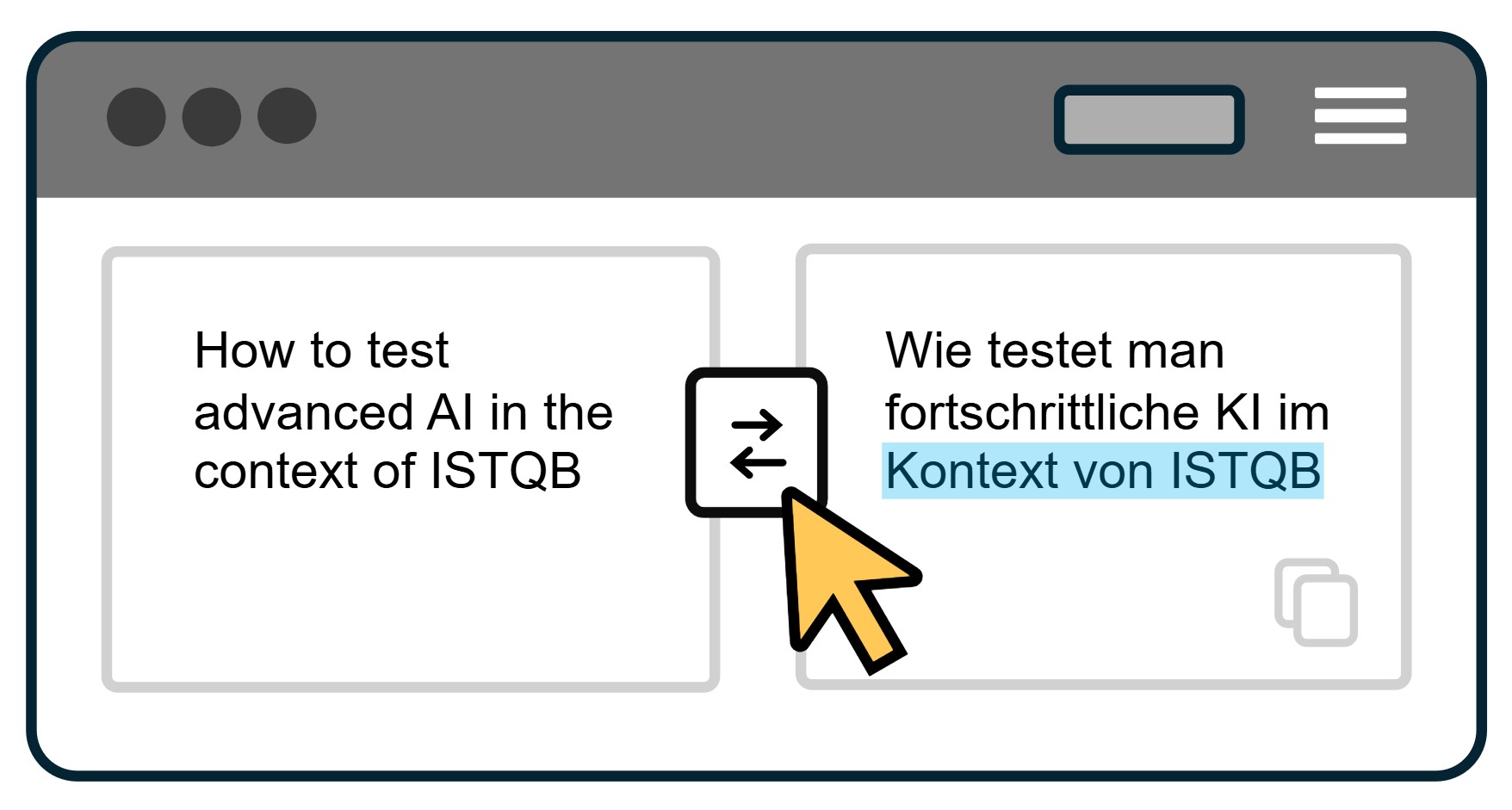
Bei diesem Review hat der Begutachter typischerweise einige Anmerkungen, die er in Form von Kommentaren genau an den Stellen im Sourcecode hinterlässt, die betroffen sind (siehe Abbildung 1).
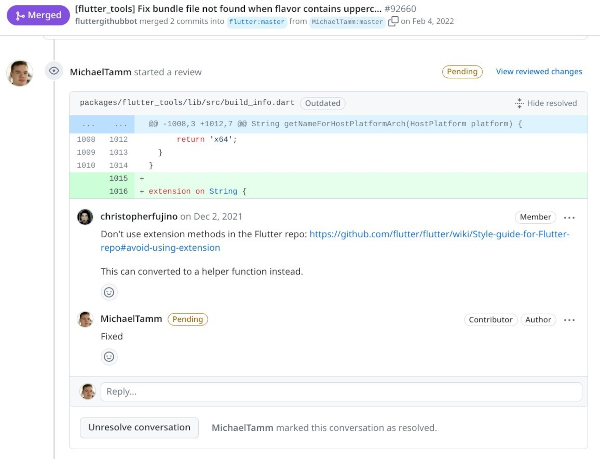
Abb. 1: Ein typisches Beispiel für einen Review-Kommentar
So ergibt sich ein Hin und Her, in dem der Autor des Pull-Requests entweder seinen Code so anpasst, wie der Reviewer vorgeschlagen hat, oder aber begründet, warum er denkt, dass sein Code genau so übernommen werden sollte.
Die zwei großen Vorteile von Code-Reviews
Wozu das alles? Tatsächlich kostet dieses Hin und Her Zeit. Gerade im Open-Source-Umfeld meistens mehrere Tage oder Wochen. Aber auch im professionellen Umfeld kosten Code-Reviews wertvolle Zeit, hier typischerweise Stunden oder wenige Tage, was sich natürlich ungünstig auf die Change-Lead-Time-Metrik ("Wie lange dauert es, bis ein Commit in der Produktionsumgebung ankommt, eine der vier DORA-Schlüsselmetriken") auswirkt, weshalb sich Code-Reviews in der Praxis noch nicht überall als Best Practice durchgesetzt haben.
Was dabei leider übersehen wird, sind die beiden großen Vorteile von Code-Reviews, die (nach Meinung des Autors dieses Artikels) die Kosten mehr als wettmachen. Diese Vorteile sind:
- Steigerung der inneren Softwarequalität sowie
- Wissensverteilung.
Worauf sollte ein Reviewer achten?
Um gleich mit einem weiteren Vorurteil gegen Code-Reviews aufzuräumen: Code-Reviews dienen nicht dazu, die äußere Softwarequalität zu verbessern, also beispielsweise Fehler im Code zu finden. Wenn bei einem Review tatsächlich mal ein Fehler gefunden wird, dann ist das lediglich ein schöner Nebeneffekt des Reviews.
Die wichtigste Frage, die sich ein Reviewer immer stellen sollte, ist nämlich nicht: "Does this code work?" (Funktioniert dieser Code?) Diese Frage sollten automatisierte Tests beantworten. Tatsächlich ist die wichtigste Frage, die ein Reviewer sich stellen sollte:
- "Will I be okay maintaining this?" – (Ist dies Code, den ich warten könnte/möchte?)
Genau darum geht es in einem Review: Die Wartbarkeit der Software sicherzustellen und damit auch eine gleichbleibende Entwicklungsgeschwindigkeit.
Auch wenn die Entwicklungsgeschwindigkeit keine der DevOps-Research-and-Assessments-Schlüsselmetriken (DORA) ist, ist sie doch eine extrem wichtige Metrik, denn je langsamer ein Entwicklungsteam wird, desto teurer wird die Weiterentwicklung/ Wartung der Software. Leider ist es das Schicksal eigentlich jedes Softwareprojekts, dass es immer komplexer wird, der Code und die Tests immer mehr werden, die Tests dadurch länger dauern und auch Refactorings zeitintensiver werden, weil neben dem Produktionscode (der dank moderner IDEs tatsächlich meist schnell geändert ist) auch zahlreiche Tests angepasst werden müssen. Dies führt wiederum dazu, dass eigentlich wichtige Refactorings nicht mehr getan werden. Ein Teufelskreis, weil genau dadurch die Wartbarkeit weiter sinkt und damit die Produktivität der Entwickler, bis irgendwann der Punkt erreicht ist, wo vor lauter Bugfixing eine Weiterentwicklung praktisch nicht mehr möglich, zumindest aber nicht mehr rentabel ist. Genau darum sind die innere Softwarequalität und damit Code-Reviews, die diese sicherstellen, so wichtig.
Aus der Hauptfrage "Will I be okay maintaining this?" lassen sich einige Unterfragen ableiten wie beispielsweise: Ist der Code gut lesbar und verständlich? Sind die Namen von Klassen, Funktionen, Variablen gut gewählt? Sind Funktionen zu lang/zu komplex? Wurden neue Klassen und Funktionen an der richtigen Stelle im Projekt eingefügt? Ist neuer Code so strukturiert, wie der Rest der Codebasis oder werden neue Architekturmuster eingeführt (was okay sein kann)? Hätte das Problem vielleicht auch mit bereits existierendem Code gelöst werden können? Ist neuer Code durch Tests abgedeckt?
Letztere Frage lässt sich sehr einfach beantworten, wenn man in die CI-Pipeline das Messen der Testabdeckung einbaut und diese Daten dann GitHub oder GitLab mitteilt, sodass in dem für einen Review typischen Diff-View nicht nur die Änderungen sichtbar sind, sondern auch die Testabdeckung in Form von grünen beziehungsweise roten Balken visualisiert wird (siehe Abbildung 2).
Abb. 2: Kleine grünen Balken vor dem Code auf der rechten Seite visualisieren, welche Codezeilen von Tests abgedeckt sind
Automatisierung von Code-Reviews
Primärziel eines Code-Reviews sollte also sein, die Wartbarkeit hochzuhalten. Natürlich kann (und sollte) man einen Build automatisiert fehlschlagen lassen, wenn beispielsweise zu lange oder zu komplexe Funktionen erkannt werden oder falls erkannt wird, dass der Code-Styleguide verletzt wurde – also eine Art automatisierter Review. Hier gilt: Alles, was automatisiert werden kann (Codeformatierung, statische Codeanalyse), sollte auch automatisiert werden. Am besten schon im Pre-Commit Hook direkt auf dem Rechner des Entwicklers und nicht erst in der CI-Pipeline.
Die automatische Codeformatierung ist nicht nur eine Erleichterung für den Reviewer, der nicht mehr nach Verletzungen der (hoffentlich vorhandenen) Coding-Guidelines schauen muss. Obendrein führen sie zu einem einheitlichen Stil in der Codebasis, sodass sich Entwickler auch sofort an eher unbekannten Stellen der Codebasis wohlfühlen. Außerdem erübrigen sich mit automatischer Codeformatierung auch die Diskussionen über die „richtige“ Formatierung, weil diese schlichtweg vorgegeben ist. Und zu guter Letzt lassen sich menschliche Entwickler auch lieber von ihrem Rechner korrigieren als von einem menschlichen Reviewer.
Die statische Codeanalyse (lint, FindBugs, eslint usw.) hilft, typische Fehler, die in der jeweiligen Programmiersprache oft gemacht werden, zu vermeiden – eine wertvolle Ergänzung in jedem Softwareprojekt. Eine weitere, oft vernachlässigte Art statischer Codeanalyse sind automatisierte Architektur-Tests, also beispielsweise das Überprüfen, ob die Abhängigkeitsregeln einer definierten Schichten-Architektur eingehalten werden, oder eine Codeänderung vielleicht doch einen Import enthält, der die gewünschte Architektur verletzen würde. Man kann aber auch selber sehr einfach Architektur-Tests schreiben, die beispielsweise durch einen einfachen Scan aller Source-Dateien und einen String-Vergleich sicherstellen, dass eine bestimmte Funktion einer Third-Party-Bibliothek, die nicht aufgerufen werden soll, auch tatsächlich nirgendwo im Sourcecode vorkommt.
Aber auch wenn automatisierte Reviews sinnvoll sind, die meisten der oben aufgeführten Fragen für gute Wartbarkeit, wie die nach guter Verständlichkeit oder guter Namensgebung, kann eben nur ein Mensch beantworten. (Es sei an dieser Stelle angemerkt, dass es zurzeit im Zuge des allgegenwärtigen KI-Hypes interessante Experimente mit einer KI als Reviewer gibt.) Und da ja möglichst kurze Feedbackzeiten immer erstrebenswert sind, ist – nach Pair Programming – der Code-Review das beste Mittel, um genau diese Fragen zu beantworten und damit Sorge dafür zu tragen, dass die Wartbarkeit und damit die Produktivität der Entwickler hoch bleibt.
Wissensverteilung durch Code-Reviews
Nachdem das Primärziel von Code-Reviews nun geklärt ist, möchte ich noch kurz auf deren zweiten großen Vorteil eingehen: Der Review durch eine zweite Person ist immer auch eine Chance, Wissen zu verbreiten – sowohl der Autor als auch der Reviewer können bei einem Review etwas lernen beziehungsweise dem anderen etwas lehren. Dies fängt an bei der Programmiersprache. (Jede Programmiersprache hat ihre eigenen Idiome, die man erst nach und nach beim längeren Verwenden lernt und verinnerlicht.) Das geht über den Einsatz der verwendeten Third-Party-Bibliotheken weiter. (Werden deren APIs korrekt benutzt? Wurden eventuell unnötig Sachen programmiert, für die eine Third-Party-Bibliothek bereits eine Lösung anbietet?) Und hört schließlich in der eigenen Codebasis auf: Auch hier könnte auffallen, dass Sachen unnötig programmiert wurden, weil der Autor eine bereits vorhandene Hilfsfunktion oder Klasse nicht kannte.
Der Reviewer schaut, ob die vorhandenen Coding-Guidelines und Architektur-Richtlinien eingehalten wurden. (Eventuell sind diese nicht einmal dokumentiert, sondern nur in den Köpfen der Entwickler vorhanden, die schon länger an dem Projekt mitarbeiten.) Jede Verletzung ist automatisch eine Gelegenheit, dem Autor diese näher zu bringen, zum Beispiel indem im Review-Kommentar ein Link zu der Regel eingefügt wird (siehe Abbildung 1).
Aber nicht nur das Dazulernen von Autor und Reviewer ist ein Vorteil, sondern auch die Tatsache, dass sich nach jedem Review nicht nur eine, sondern zwei Personen mit dem Code auskennen. Dies reduziert den Bus-Faktor, also das Risiko des Ausfalls eines Team-Mitglieds, deutlich.
Code-Reviews kosten Zeit. Wie geht's am schnellsten?
Ich möchte noch einmal auf die Problematik der Zeit-Kosten zu sprechen kommen, denn es lässt sich ja nicht leugnen, dass sich durch den Review-Prozess eine zeitliche Verzögerung vom initialen Erstellen einer Änderung bis zum Merge der Änderung in den Hauptbranch ergibt. Auch wenn das Endergebnis durch die Diskussionen, Verbesserungen und Re-Reviews ein besseres ist, als der initiale Änderungsvorschlag, dauert der Review-Prozess Zeit. Bei Open-Source-Projekten kann sich dies durchaus über mehrere Wochen hinziehen.
Dies ist im professionellen Umfeld natürlich nicht hinnehmbar, aber zum Glück kann der Review-Prozess in einem solchen Umfeld auch wesentlich schneller durchgeführt werden. Am schnellsten geht es, nachdem der Reviewer den ersten Review durchgeführt und alle seine Anmerkungen gemacht hat, wenn der Reviewer zusammen mit dem Autor in einem direkten Gespräch (Face-to-Face oder via Videokonferenz) alle Anmerkungen durchgeht. Hierbei kann schnell ein gemeinsames Verständnis hergestellt werden, wie der Code am Ende aussehen sollte, sodass oftmals ein zweiter Review gar nicht mehr nötig ist.
Bleibt noch die Zeitspanne vom Erstellen eines Pull-Requests bis zum ersten Review. Um diese so kurz wie möglich zu halten, empfiehlt sich entweder eine automatische Zuweisung oder aber auch eine manuelle Zuweisung des Reviewers, sobald ein Pull-Request erstellt wird. Außerdem sollten Reviews eine höhere Priorität haben, als selber Code zu schreiben: Ganz im Sinne von Kanban sollte möglichst wenig produzierter Code auf Halde liegen. Deshalb sollte ein Programmierer nur dann tatsächlich programmieren dürfen, wenn er nichts mehr zu reviewen hat. Außer er ist gerade im Flow und Unterbrechungen sollen vermieden werden. Aber auch dann sollte gelten, der Review ist bei der nächsten Gelegenheit/Pause durchzuführen, bevor weiterprogrammiert wird.
Tipps und Tricks
Sollten Sie als Reviewer einmal einen Pull-Request zum Review vorgesetzt bekommen, der – sagen wir – mehr als 50 geänderte Dateien enthält, so sollte im Vorfeld im Team vereinbart worden sein, dass es in Ordnung ist, einen solchen Pull-Request abzulehnen, weil er zu umfangreich ist. Jeder Entwickler sollte in der Lage sein, das Problem, an dem er arbeitet, in so kleine Teilprobleme zu zerlegen, dass er wenigstens einen Pull-Request am Tag erstellen kann. Sollte jemand keinen Pull-Request innerhalb von zwei Arbeitstagen erstellen, sollten die Alarmglocken läuten, weil da höchstwahrscheinlich etwas schief läuft.
Ein Pull-Request sollte immer atomar sein und nur eine einzige Änderung beinhalten. Das macht nicht nur dem Reviewer die Arbeit leichter, sondern ermöglichst es auch, problematische Änderungen später einfach rückgängig zu machen.
Außerdem ist es empfehlenswert, falls für die Implementierung eines neuen Features ein Refactoring nötig ist, für dieses Refactoring einen eigenen Pull-Request zu erstellen. Hierzu ist etwas Disziplin bei den Entwicklern gefragt, denn oft fällt es erst mitten beim Programmieren auf, dass ein Refactoring sinnvoll ist. Da man dann meistens schon einige Dateien geändert hat, denken Entwickler oft, sie machen das Refactoring schnell mit. Dies erschwert jedoch den Review, weil nur schwer unterschieden werden kann, welcher Code durch das Refactoring geändert wurde (sehr wahrscheinlich mithilfe eines automatisierten Umbenennen-, Extrahieren-, Inlinen- oder Verschieben-Refactorings in einer IDE) und welcher Code tatsächlich neu geschrieben wurde. Auch hier sollte vorher im Team vereinbart worden sein, dass Reviews von solchen Pull-Requests abgelehnt werden dürfen. Die bessere Vorgehensweise, die wie gesagt etwas Disziplin von den Entwicklern erfordert, ist: Sobald erkannt wird, dass ein Refactoring sinnvoll ist, die gemachten Änderungen zunächst zu "shelfen", dann das Refactoring durchzuführen und dafür einen eigenen Pull-Request zu erstellen.
Das Entwicklerteam könnte sogar vereinbaren, dass für Pull-Requests, die nur Änderungen durch automatisierte Refactorings enthalten, auch ohne manuellen Review in den Hauptbranch gemergt werden dürfen, falls der CI-Build grün ist.
Wie sollten Review-Kommentare aussehen?
Zu guter Letzt möchte ich noch ein paar Worte über die für einen Code-Review so typischen Review-Kommentare fallen lassen. Auch wenn es eigentlich selbstverständlich sein sollte, Review-Kommentare sollten niemals Beleidigungen enthalten, sondern immer respektvoll formuliert sein. Sie sollten auch keine Aufforderung sein, etwas zu ändern, sondern vielmehr als Einstieg in eine Diskussion formuliert werden, zum Beispiel so: "Ich denke ... Was meinst du?"
Es ist auch wenig hilfreich, in einem Review-Kommentar nur zu schreiben, was einem nicht gefällt. Man sollte immer konkrete Alternativen formulieren. Falls dem Reviewer klar ist, wie der Code seiner Meinung nach aussehen sollte, dann bieten GitHub & Co. die Möglichkeit, mit einem Mausklick die beanstandeten Codezeilen in den Editor für den Review-Kommentar zu kopieren, sodass der Reviewer diese Zeilen ganz schnell nach seinen Vorstellungen ändern kann (siehe Abbildung 3).
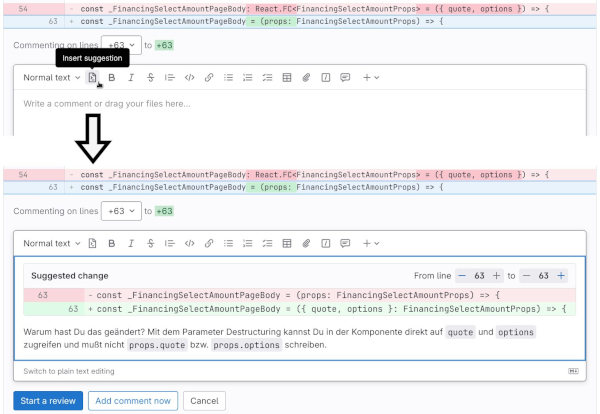
Abb. 3: Mithilfe von Insert Suggestion kann der Reviewer sehr schnell eine Codeänderung vorschlagen
Darüber hinaus kann der Autor später, wenn er mit der vorgeschlagenen Änderung einverstanden ist, diese auch mit einem einzigen Mausklick in seinen Pull-Request übernehmen.
Und wenn Sie als Reviewer einmal über einen besonders guten Codeabschnitt stolpern, freut es jeden Autor, wenn Sie ein kurzes Lob (z. B. "+1" oder "sehr schön gelöst :)") hinterlassen.
Sieben zentrale Beobachtungen zu Code-Reviews
- Code-Reviews bieten zwei große Vorteile: Steigerung der inneren Softwarequalität sowie Wissensverbreitung.
- Code-Reviews werden nicht in erster Linie gemacht, um Fehler zu finden, sondern um eine hohe Wartbarkeit und damit eine gleichbleibende hohe Entwicklungsgeschwindigkeit zu gewährleisten.
- Einige Aspekte von Code-Reviews wie Code-Formatierung und statische Codeanalyse können und sollten automatisiert werden.
- Code-Reviews führen zu einer höheren Change-Lead-Time. Um dem entgegenzuwirken, sollten Code-Reviews eine höhere Priorität als normale Entwicklungsarbeit haben.
- Reviewer sollten Pull-Requests ablehnen dürfen, die zu umfangreich oder nicht atomar sind, also beispielsweise umfangreiche Refactorings und neue Features umfassen.
- Review-Kommentare sollten keine unkonstruktive Kritik sein, sondern Alternativen aufzeigen und als Einstieg in eine Diskussion formuliert sein.
Fazit
Ich hoffe, ich konnte Sie von den Vorteilen von Code-Reviews überzeugen und ein paar hilfreiche Tipps geben. Falls Sie noch keine Code-Reviews in Ihrem beruflichen Umfeld einsetzen, vielleicht probieren Sie es ja im nächsten Sprint einmal als Experiment aus. Sie wären in guter Gesellschaft, denn schließlich gehören Code-Reviews bei den großen Software-Firmen wie Google, Facebook, Amazon und Microsoft schon seit Jahren zum Daily Business. Für weiterführende Information möchte ich Ihnen noch die Code Review Guidelines von Google empfehlen: google.github.io/eng-practices/