Machine Learning für alle
Maschinelles Lernen (ML) besitzt enormes Potenzial, um Geschäftsprozesse zu vereinfachen, und wird von großen Unternehmen bereits erfolgreich eingesetzt. Daneben bewegen sich kleine und mittelständische Unternehmen in sich stetig wandelnden Geschäftsprozessen und finden den Einstieg in die Verwendung von ML zur Optimierung nicht. Das vom BMBF geförderte Forschungsprojekt ImPaKT des HNI Paderborn widmet sich genau der Anwendung von ML-Methoden für eine intelligente Auswirkungsanalyse von Engineering Change Requests (ECR). Mehrere kleine und mittelständische Unternehmen, wie die Hofmann Mess- und Auswuchttechnik GmbH & Co. KG, wirken aktiv mit und geben Anwenderfeedback: Besitzen die neuen Konzepte das Potenzial, sich in den Unternehmen durchzusetzen?
Akronyme
- AutoML: Automated Machine Learning
- BERT: Bidirectional Encoder Representations for Transformers
- BMBF: Bundesministerium für Forschung und Entwicklung
- ECR: Engineering Change Request
- EVA: Eingabe – Verarbeitung – Ausgabe
- GNN: Graph Neural Networks
- MBSE: modellbasiertes Systems Engineering
- MLOps: Machine Learning Operations
- NLP: Natural Language Processing
- NLP4RE: NLP for Requirements Engineering
- RE: Requirements Engineering
Herausforderungen im Systems Engineering
Technische Systeme werden ständig komplexer. Systems Engineering ist eine hilfreiche Methode, um diese Komplexität zu bearbeiten [Gra22]. Beim modellbasierten Systems Engineering (MBSE) werden Elemente wie Pflichten und Lastenhefte modellbasiert in einem Systemmodell abgebildet. Diese Elemente können untereinander vernetzt sein. Gerade kleine und mittelständische Unternehmen denken nicht in Systemen. Sie sind aber ebenfalls von den Herausforderungen der Komplexität und Vernetztheit betroffen. Abbildung 1 stellt die lückenhaften Prozesse schematisch dar.
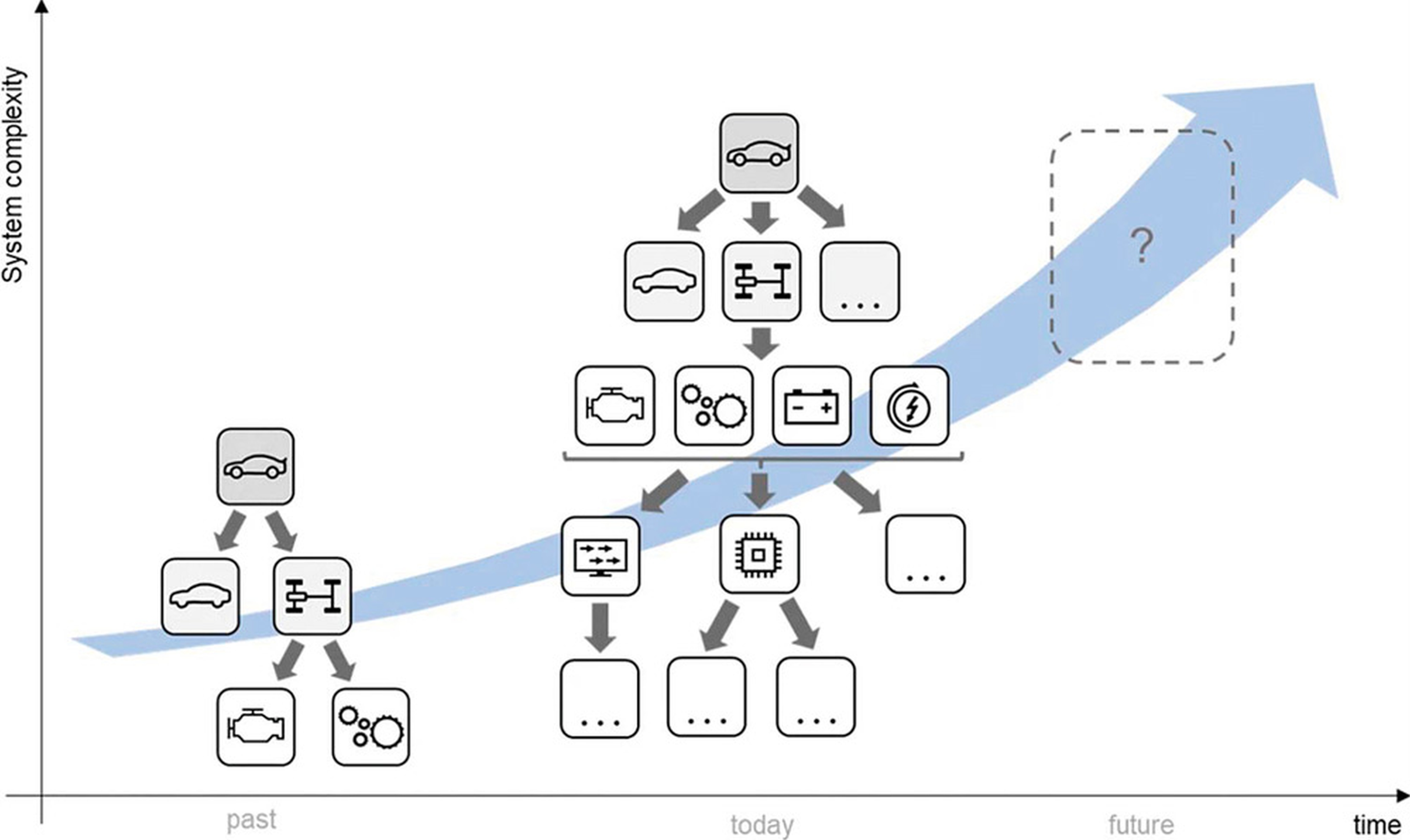
Abb. 1: Ständig wachsende Komplexität bei der Entwicklung technischer Systeme
Abbildung 2 zeigt die Problematiken in kleinen und mittelständischen Unternehmen hinsichtlich des Engineering-Change-Managements. Dort liegen zwar Daten vor, aber häufig in separaten Dateien oder Systemen mit uneindeutigen Bezugsschlüsseln.
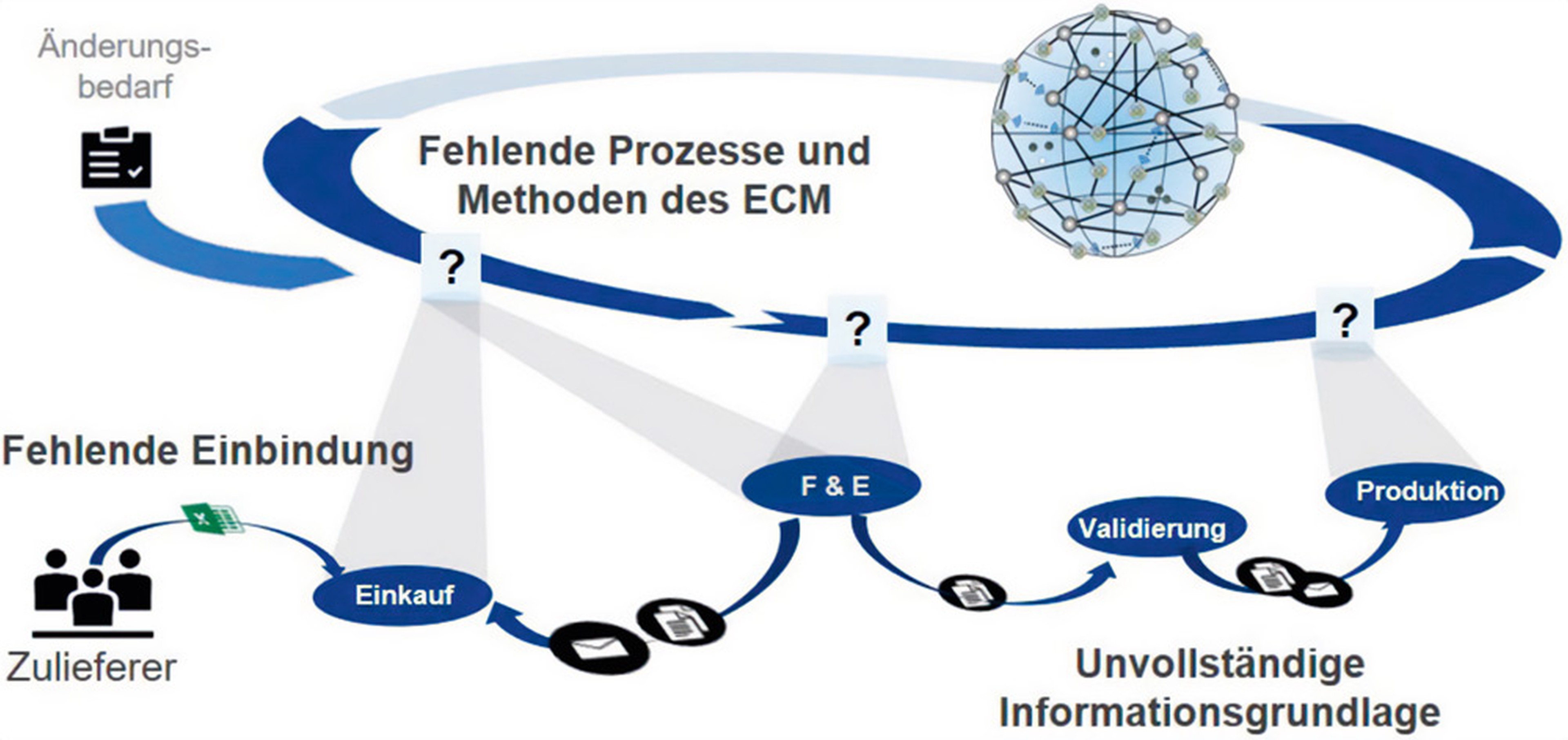
Abb. 2: Problematiken in KMU hinsichtlich des Engineering-Change-Managements (Quelle: ImPaKT)
So kann beispielsweise eine Kundenmaterialnummer einer Reihe interner Materialnummern entsprechen, sodass an dieser Stelle keine eindeutige Beziehung zwischen externer und interner Materialnummer vorliegt. Diese kleine Uneindeutigkeit kann zusammen mit anderen ähnlichen Uneindeutigkeiten zu Undurchschaubarkeit des Datenbestands führen. Schauen wir als Datenanalyst auf diesen, stellt er sich als lückenhaft und unvollständig dar. Das erschwert die Anwendbarkeit von ML-Methoden. Zudem benötigen ML-Modelle große Datensätze, auf welche sie trainiert werden. Diese sind bei KMUs meist in der Größe nicht vorhanden.
Beim Requirements Engineering können erfahrungsgemäß die teuersten Fehler passieren. Anforderungen werden in Lastenheften meist in natürlicher Sprache verfasst. Dabei treten Duplikate, ungenaue und sogar fehlende Anforderungen auf. Von KI-Methoden erwarten wir andererseits, dass genau diese Probleme im Datenbestand gelöst werden.
NLP mit BERT
Um diesen Herausforderungen zu begegnen, nutzen wir Natural Language Processing (NLP), das ist ein Teilbereich der KI und der Computerlinguistik. Wir nutzen ein KI-Modell, welches BERT (Bidirectional Encoder Representations for Transformers) heißt, in Anlehnung an die bekannte Figur aus der Sesamstraße. BERT erschien 2019 und ist eines der ersten Transformer-Modelle. Ein Transformer bezeichnet in diesem Fall eine Methodik, um eine Zeichenfolge in eine andere Zeichenfolge zu überführen. Das einfachste Beispiel sind Übersetzer. Transformer gehören zu den Deep-Learning-Architekturen. Die Transformer-Architektur, die bei BERT als Basis verwendet wurde, diente übrigens auch als Basis zur Entwicklung von ChatGPT.
Abbildung 3 zeigt exemplarisch die Verarbeitungsschritte, welche eine Anforderung mit BERT durchläuft. Für den Anforderungssatz wird zunächst mit Verfahren aus der KI ein Vektor berechnet, welcher dann an sogenannte Blöcke weitergereicht wird. Die Architekturen der Blöcke sind identisch zueinander und bestehen jeweils aus denselben zwei KI-Modellen und einigen Funktionen zur Stabilisierung der Berechnungen. BERT ist also mehr als nur ein KI-Modell: Es kombiniert die Stärken zweier verschiedener KI-Architekturen in ursprünglich sechs identischen Blöcken, wodurch das Modell mehr und mehr über die Daten lernen kann.
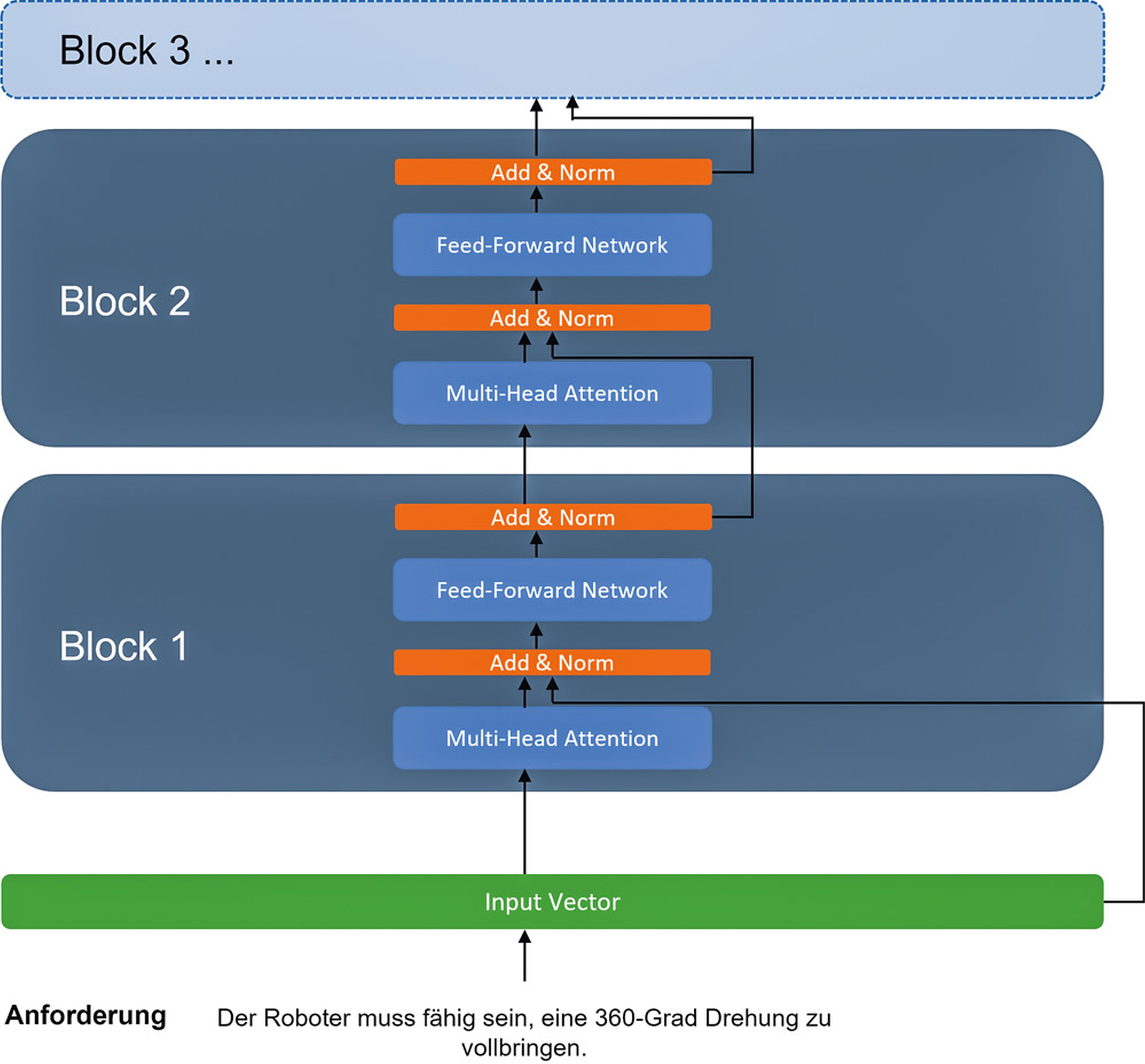
Abb. 3: Verlauf eines einzelnen Satzes durch BERT
Von der Herausforderung zur Lösung
Das übergeordnete Ziel von ImPaKT ist es, die Auswirkungen einer technischen Änderung im gesamten Systemmodell hervorzuheben. Das können Anforderungen oder technische Details des Produktionsprozesses sein. Zwischen diesen Elementen bestehen Verbindungen unterschiedlicher Art. So kann die technische Realisierung von einer oder mehreren Anforderungen abhängen. Es besteht eine Abhängigkeitsbeziehung (technisch: requires). Diese Verbindungen möchten wir präzise modellieren. Wir benötigen ein mathematisches Modell, aus dem wir Ähnlichkeiten und Abhängigkeiten zwischen einzelnen Anforderungen automatisch ableiten.
Die KI versteht keine natürliche Sprache. Daher werden Textdaten mittels Techniken aus der Informatik und der linearen Algebra in eine Form gebracht, welche die KI „versteht“. Anschließend wird das KI-Modell auf diese Form iterativ trainiert, sodass es Zusammenhänge in den Textdaten erkennt, die dem menschlichen Auge vor allem bei sehr großen Datenmengen entgehen. Darüber hinaus kann das KI-Modell nun auch unbekannte Textdaten analysieren. Dieses KI-Modell kann mit weiteren Daten einer bestimmten Domäne verfeinert werden. Vereinfacht gesagt „lernt es die Domäne, beispielsweise Sondermaschinenbau“. In der Praxis werden ähnliche KI-Modelle in großen Rechenzentren vortrainiert und anschließend auf sogenannten Modelhubs als Open-Source-Modelle veröffentlicht. Andere Entwickler können sie dann ebenfalls verwenden und auf eine Domäne verfeinern. Die Verfeinerung braucht deutlich weniger Rechenleistung als das Vortraining, wodurch sie auch auf einem lokalen Rechner mit der Rechenleistung einer passenden Grafikkarte auf einem kleineren Datensatz angewendet werden kann. Auf diese Weise kann theoretisch jedermann mit einem leistungsfähigen Rechner KI-Modelle verfeinern. Nun gibt es zwei Möglichkeiten der Verfeinerung: überwachtes Lernen und unüberwachtes Lernen. Bei dem überwachten Lernen (Supervised Learning) werden die Daten manuell „beschriftet“. Beispielsweise werden zwei Anforderungen als „eng verbunden“ gekennzeichnet. Anschließend „lernt“ das KI-Modell auf diesem Datensatz, was „eng verbunden“ bedeutet. Der manuelle Schritt kann dabei recht arbeitsintensiv sein.
Beim unüberwachten Lernen (Unsupervised Learning) entfällt dieser manuelle Schritt und das KI-Modell lernt auf unangepassten Datensätzen. Nun wird die KI versuchen, die Daten iterativ besser zu modellieren. Unüberwachtes Lernen ist weit verbreitet im ML-Feld des Clustering und bei der semantischen Suche, um Schlüsse aus Daten zu ziehen, die ein Mensch wegen der enormen Komplexität nicht erkennen kann.
Von Ontologien und Knowledge-Graphen
Anforderungen über den Entwicklungsund Produktlebenszyklus nachverfolgen zu können (Traceability), ist aus der Software- und Produktentwicklung nicht mehr wegzudenken. Es gibt bereits einen Markt an Traceability-Werkzeugen. Verlinkungen zwischen den Artefakten werden meist manuell erstellt. An dieser Stelle könnten KI-Methoden unterstützen und automatisiert Verlinkungen erstellen oder vorschlagen. Um diese Methoden nutzen zu können, benötigen wir zunächst eine formale Repräsentation der Daten, ein Systemmodell. Das allein reicht noch nicht für die Anwendung einer KI-gestützten semantischen Analyse. Denn wir benötigen zweitens das jeweilige formale Konzept dieser Daten. Dieses formale Konzept ist eine Ontologie. Daten und Ontologie zusammen formen den sogenannten Knowledge Graph. Es gibt bereits mächtige Knowledge Graphs, die im Einsatz sind, wie den Google-Knowledge-Graph oder den Facebook-Graph [Kop17,Ohs98].
Abbildung 4 zeigt eine Ontologie aus der Domäne „Kunst“ sowie die Anwendung auf Daten. In unserem Forschungsprojekt fokussieren wir uns auf kleine, domänenspezifische Ontologien.
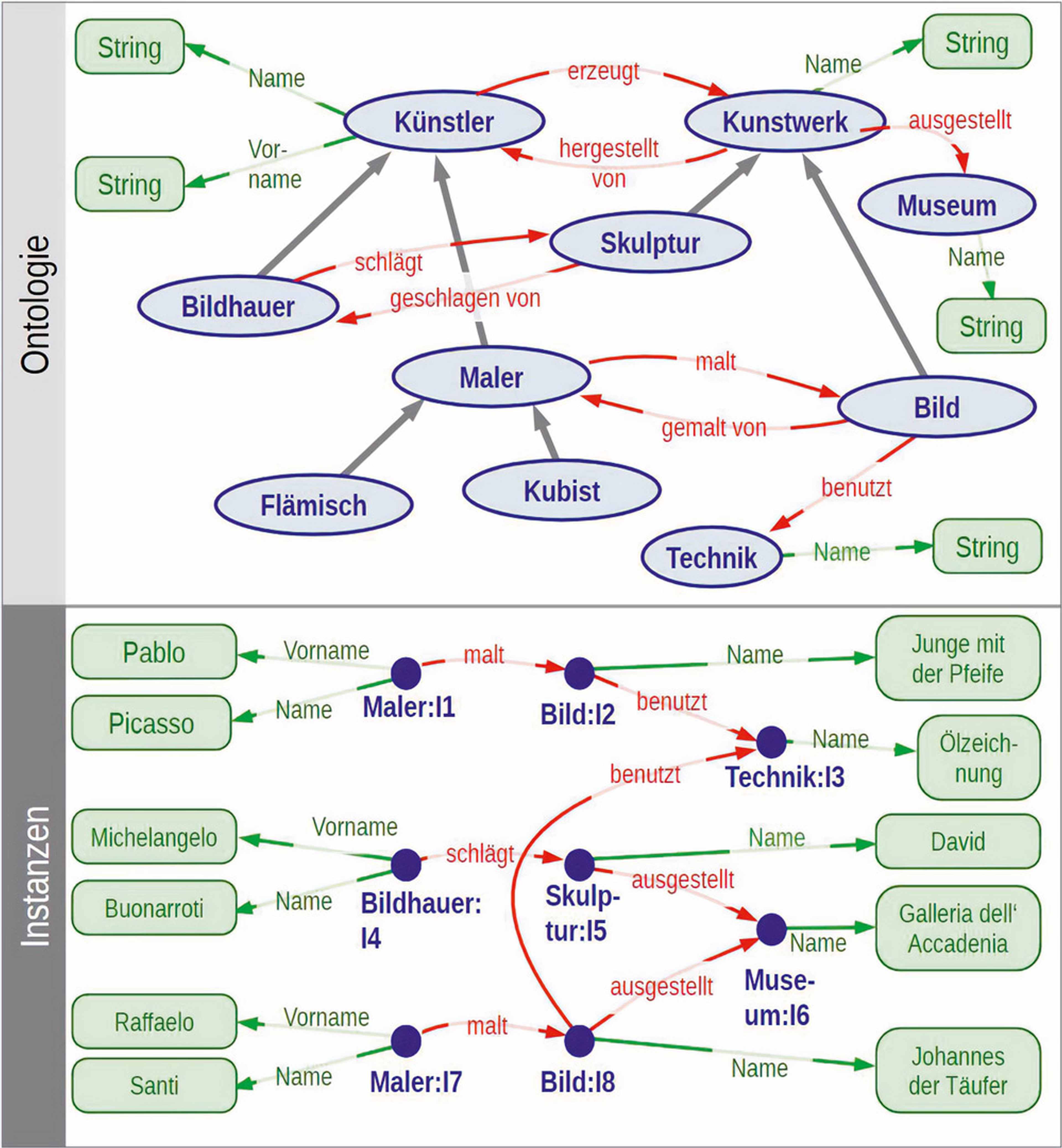
Abb. 4: Beispiel für eine Ontologie [WIK23]
Es existieren unterschiedliche Strategien, um eine Ontologie zu erstellen. Eine konzentriert sich auf übereinstimmende Wörter oder Informationen zwischen Dokumenten und zieht dazwischen Verknüpfungen. Bei der datengesteuerten Ontologie stehen, wie der Name bereits vermuten lässt, die Daten im Fokus. Da wir bereits über die Daten verfügen, ist es wichtig, eine Ontologie zu erstellen, welche die Struktur der Daten analysieren und die notwendigen Schritte definieren kann, um sie in Form von Verknüpfungen zu integrieren. Des Weiteren kann eine Ontologie auch modellbasiert erstellt werden.
Die Definition des Zwecks einer Ontologie ist der erste und wichtigste Schritt in jedem Analyseprozess. Im ImPaKT-Forschungsprojekt ist dieser Zweck die Auswirkungsanalyse von Änderungen im Produktionsprozess. Die Datengrundlage ist dabei in kleinen und mittelständischen Unternehmen sehr heterogen, sodass es keine allgemein vordefinierte Lösung für jeden geben kann. Hier zeigen sich die Stärken des modellbasierten Systems Engineering auf der einen und der KI-gestützten Analyse auf der anderen Seite. Das modellbasierte Systems Engineering schafft die Grundlage und KI-Methoden knüpfen an und erweitern die Möglichkeiten der Analyse. Wie im Konkreten die KI-gestützte Analyse im ImPaKT-Projekt aussieht, beschreiben wir im nachfolgenden Abschnitt. Zentrale Technologie ist das Natural Language Processing. Wir haben die zur Datenvorbereitung und -analyse notwendigen Zwischenschritte in einer sogenannten in sich geschlossenen Pipeline realisiert. Diese erhält Inputdaten, verarbeitet diese und gibt sie anschließend weiter. Grob gesagt erinnert dies an die langjährig bekannte EVA-Struktur der Datenverarbeitung, wenngleich die verwendeten Technologien sehr modern sind.
ML mit der NLP-Pipeline
Die von uns entwickelte Pipeline erzeugt einen Knowledge-Graph vollautomatisch aus Textdateien mit Anforderungen. Dieser kann als Grundlage für weitere Analysen oder zur Anzeige verwendet werden. Er enthält essenzielle semantische Verbindungen zwischen den Knoten mit beschreibenden Attributen. Die Knoten entsprechen den Anforderungen und die Verbindungen können Tracelinks unterschiedlicher Art darstellen. Diese Ergebnisse können nun vom Requirements Engineer weiter beurteilt werden. Mit der Pipeline haben wir ein hybrides System entwickelt, das
- neuste KI-Modelle und
- regelbasierte Systeme
über mehrere Softwarekomponenten hinweg miteinander kombiniert. So nutzen wir die Vorteile beider Strategien. Wir legen unseren Fokus auf die Verbesserung des unüberwachten Machine Learning, um die zeitraubende manuelle Annotation der Datensätze zu minimieren. Denn wir möchten Mehrarbeit für die Nutzer vermeiden. Ein Ziel dabei ist es, die Hürden und zeitlichen Anforderungen für die Einführung neuartiger Methoden so gering wie möglich zu halten. In kleinen und mittelständischen Unternehmen sind die Kapazitäten zur Einführung neuer Systeme, Prozesse oder Werkzeuge eng bemessen. Gleichzeitig schaffen wir mit dieser Architektur ein System, das skalierbar ist.
Die Nutzung der von uns entwickelten Pipeline kann Requirements Engineering-Prozesse vereinfachen und verkürzen und die Komplexität von Traceability etwas zähmen. Dennoch wurde diese Pipeline im Rahmen des Forschungsprojekts exemplarisch umgesetzt. Die nächsten Schritte werden darin bestehen, den praktischen Einsatz bei möglichen Anwendern zu prüfen. Dabei haben wir bereits jetzt die Optimierung der Rechenzeit im Visier, um die Hürden für die Einführung bei KMU weiter zu senken. Mit automatischem Triggering der Pipeline bei neuen Daten kann der Graph für ein Projekt immer auf den neuesten Stand gehalten werden, um Systems Engineers dabei zu helfen, ihre Lastenhefte effizienter und robuster zu verarbeiten.
ML einfach anwenden können
Wie können Systemanalysten diese Möglichkeiten der Analyse nun praktisch nutzen? So wie es integrierte Entwicklungsumgebungen (IDE) für die Softwareentwicklung gibt, brauchen auch Systemanalysen Werkzeuge, um ML-Methoden einfach nutzen zu können. Es gibt bereits KI-Toolkits oder ML-Workbenches und der Markt für derartige Werkzeuge wächst. Im Rahmen des Forschungsprojekts nutzen wir ein Open-Source-Framework, um einen Workflow-Manager zu erstellen. Dies ist eine einfache Weboberfläche, mit der ein Systemanalyst die oben geschilderte Pipeline auf eigene Daten anwenden kann. In dieser Oberfläche können eine oder mehrere derartige Pipelines und Analysen hintereinander- oder parallel gestartet werden. Abbildung 5 stellt dieses Zusammenspiel schematisch dar.
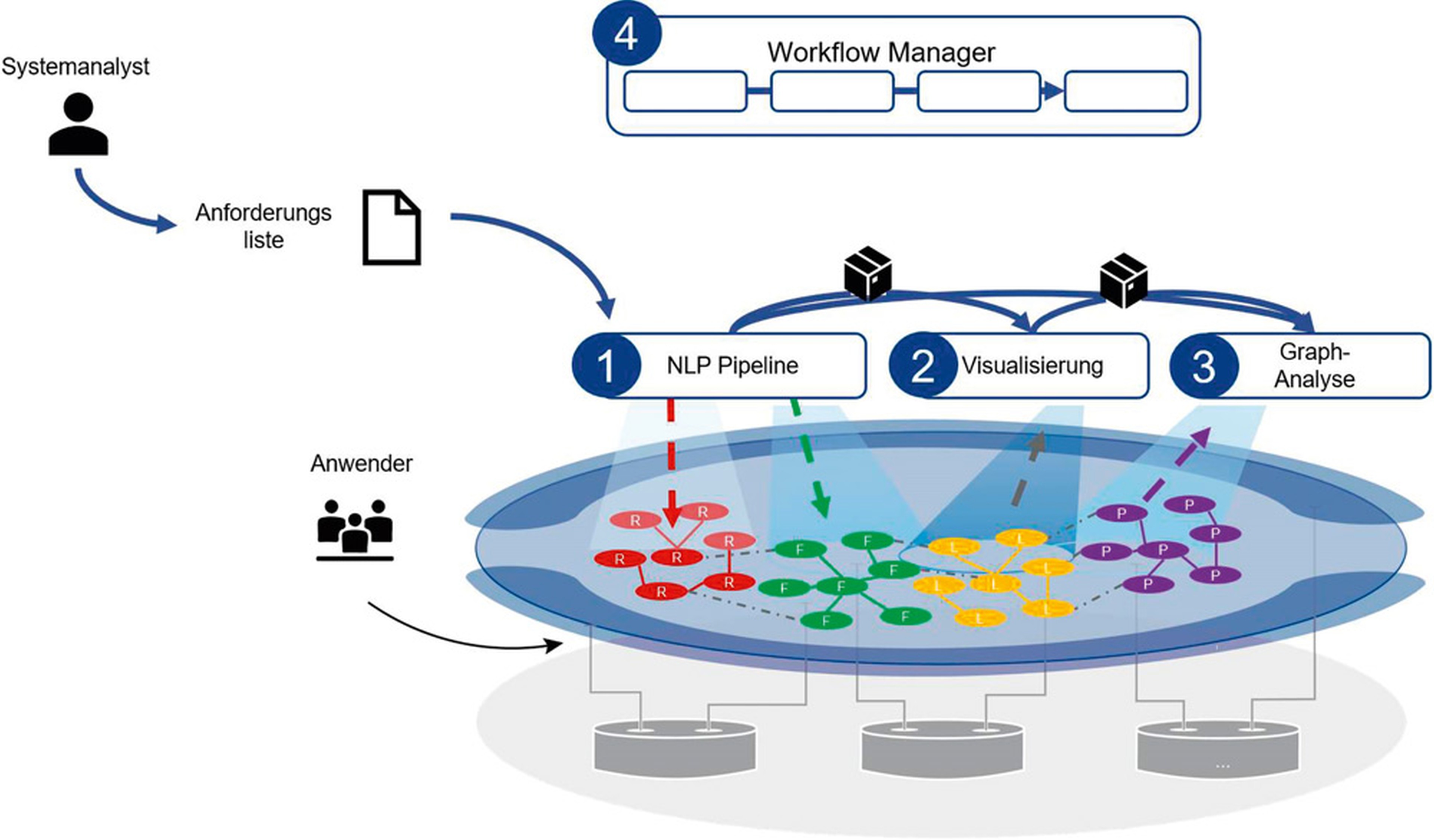
Abb. 5: Einbindung der Pipeline in den Gesamtkontext des Projekts und Zusammenspiel mit anderen Analyse- oder Visualisierungsservices
Systemintegration: ML und Systems Engineering zusammenbringen
Im Kern nutzt die Systemtechnik das Systemdenken, eine Methode zur Erforschung und Anwendung wirksamer Maßnahmen in komplexen Szenarien. Anstatt das System zu zerlegen, wird das gesamte System mit seinen Knotenpunkten und Beziehungen betrachtet. Diese Systeme helfen uns, Synergien zu verstehen, die einen gewissen Grad an Komplexität zwischen den Beteiligten aufweisen. Anstatt ein Problem zu lösen, wird eine „Lösung“ vorgeschlagen, welche dem Anwendungsfall am besten entspricht. Dieser Ansatz verbindet Fachwissen und künstliche Intelligenz. So lässt sich Komplexität reduzieren und Innovation in verschiedenen Branchen fördern, in denen Software-Systemtechnik eingesetzt wird, zum Beispiel in der Automobilindustrie, im Gesundheitswesen oder in der Fertigung.
In unserem Forschungsprojekt steht die Auswirkungsanalyse im Fokus. Wir möchten die potenziellen Folgen einer Änderung oder die benötigten weiteren Änderungen abschätzen können [Boh96]. Es kann unterschiedliche Arten von Auswirkungen geben: auf die Rückverfolgbarkeit, auf die Abhängigkeiten oder auf die Erfahrungen. Eine wesentliche Innovation in der Auswirkungsanalyse können KI-Methoden erreichen. Sie können die Leistung der Klassifizierung von Knoten oder der Vorhersage von Verbindungen steigern. Jedoch gibt es im Systems Engineering feste und standardisierte Prozesse. Nach der Verallgemeinerung kann die KI-Analyse auf verschiedene Anwendungsfälle zugeschnitten und optimiert werden. Die Standardisierung stellt eine Hürde dar, die beim Einsatz von KI-basierten Anwendungen zu bewältigen ist.
Gerade in den vergangenen Wochen ist das Interesse an Künstlicher Intelligenz mit der Beteiligung von Microsoft an OpenAI sprungartig angewachsen. Wir verfolgen mit dem Forschungsprojekt Im-PaKT Möglichkeiten, um vor allem langfristig Geschäftsprozesse zu verbessern. Dabei untersuchen wir die Eignung von ML-Technologien. In enger Abstimmung mit möglichen Endanwendern evaluieren wir diese Eignung und setzen dieses Feedback ein, um die Analysemöglichkeiten stets weiter zu verbessern. Denn wir haben den Anspruch, für jeden Anwendungsfall die am besten passende Lösung zu finden. Schon Darwin wusste: Only the fittest survives. Das ImPaKT-Forschungsprojekt wird vom BMBF gefördert.
Weitere Informationen
[Boh96] S. A. Bohner, R. S. Arnold, Software Change Impact Analysis, IEEE Computer Society Press, 1996
[Gra22] I. Gräßler, D. Preuß, L. Brandt, M. Mohr, Efficient Extraction of Technical Requirements Applying Data Augmentation, in: IEEE Int. Symposium on Systems Engineering (ISSE), 2022
[Hap06] H. Happel, S. Seedorf, Applications of Ontologies in Software Engineering, in: 2nd Int. Workshop on Semantic Web Enabled Software Engineering, 2006
[Hic19] H. Hick, M. Bajzek, C. Faustmann, Definition of a system model for model-based development, in: SN Appl. Sci. 1, 1074 (2019), siehe:
https://doi.org/10.1007/s42452-019-1069-0
[Kop17] O. Kopp, Wie funktioniert der Knowledge Graph von Google?, siehe:
https://blog.searchmetrics.com/de/knowledge-graph-funktionsweise/
[Mut19] E. C. Mutlu, T. Oghaz, A. Rajabi, I. Garibay, Review on Learning and Extracting Graph Features for Link Prediction, 2019, siehe:
https://arxiv.org/pdf/1901.03425
[Ohs98] Y. Ohsawa, N. E. Benson, M. Yachida, KeyGraph: automatic indexing by co-occurrence graph based on building construction metaphor, in: Proc. IEEE Int. Forum on Research and Technology Advances in Digital, 1998
[WIK23] Ontology Engineering, wikipedia, siehe:
https://en.wikipedia.org/wiki/Ontology_engineering, 2023