

1996 arbeitete ich für einige Zeit im Silicon Valley bei Taligent, einem Joint Venture von Apple und – meinem damaligen Arbeitgeber – IBM. Java war gerade in einer frühen Alpha-Version erschienen, und ich war sofort fasziniert. So fasziniert, dass ich versuchte, ein Treffen mit James Gosling zu arrangieren, der gerade Java erfunden hatte und nur wenige Kilometer entfernt bei Sun Microsystems saß. Das Treffen kam nie zustande.
Über zwanzig Jahre später waren wir dann plötzlich beide Kollegen bei Amazon Web Services (AWS) – und James Gosling, von 2017 bis 2024 Distinguished Engineer bei AWS, war nur noch eine Slack-Nachricht entfernt. Diese kleine Anekdote steht sinnbildlich für die Reise, die Java und sein Ökosystem in 30 Jahren zurückgelegt haben: von einer exotischen Neuheit im Silicon Valley zu einer Technologie, die die gesamte IT-Industrie durchdrungen und die Basis für Anwendungen gelegt hat, auf denen viele andere Industrien aufbauen.
Die Prognosen von 1996
Ein Blick zurück auf den Originalartikel offenbart einige interessante Vorhersagen. „Vorbei sind [...] die Meinungsverschiedenheiten um die Vorherrschaft einzelner Betriebssysteme“, schrieb ich damals. „Das Universum des Anwenders wird dann sehr schnell – wahrscheinlich schneller als die meisten von uns dies vermuten würden – nicht mehr das Betriebssystem sein, sondern der Web-Browser.“ Und weiter: „Nicht die Anzahl der Anwendungen, die es für ein bestimmtes API gibt, wird also für die Wahl eines Betriebssystems entscheidend sein, sondern andere Eigenschaften wie z. B. die Robustheit, der Preis und der Support könnten im Mittelpunkt stehen.“
Heute, 30 Jahre später, lässt sich Bilanz ziehen: Die Grundaussagen waren richtig, viele der zitierten Technologien sind heute nicht mehr relevant. Drei-Schichten-Architekturen mit CORBA-Objekten auf dem mittleren Tier? Der Architekturansatz war goldrichtig – nur hießen die Technologien dann REST, Spring Boot und Microservices statt CORBA. Der „Universal Client“? Er kam – aber nicht als Browser-Terminal, sondern als Smartphone. Just-in-Time-Compiler für Java? Absolut eingetroffen und ein zentraler Faktor für Javas Erfolg im Enterprise-Bereich. Java als integraler Bestandteil aller Betriebssysteme? Eingetroffen, aber anders als gedacht: nicht als Applet-Runtime im Browser, sondern als Backend-Sprache, als Grundlage von Android, als Rückgrat von Enterprise-Systemen weltweit.
Einiges kam auch völlig anders. Java Applets – damals der Inbegriff der Java-Revolution – verschwanden vollständig. OpenDoc und das Projekt „Arabica“ (OpenDoc ähnliche Java-Beans-Komponenten), das ich 1996 als vielversprechenden Prototypen von der JavaOne beschrieb, wurden nie relevant. Und CORBA, das damals als Schlüsseltechnologie für verteilte Systeme galt, wurde durch weniger komplexe Alternativen ersetzt.
Und die Frage nach dem Betriebssystem? Sie wurde tatsächlich irrelevant. Ob Windows, macOS, Linux oder ChromeOS – die Anwendungen laufen im Browser, in der Cloud, auf dem Smartphone. Das Betriebssystem ist zur Infrastruktur geworden, über die niemand mehr allzu lange nachdenkt.

Abb. 1: Der Artikel von 1996
Das Muster: wenn Innovation zur Selbstverständlichkeit wird
Aus dieser 30-jährigen Retrospektive lässt sich ein Muster ableiten, das weit über Java hinausgeht: Die Grenze dessen, was als „Infrastruktur“ gilt – also als selbstverständlich vorausgesetzt wird – verschiebt sich kontinuierlich. Was gestern noch Differenzierungsmerkmal war, ist heute eine Selbstverständlichkeit – und so manche Fachanwendung lässt sich bereits durch wenige Prompts an ein KI-Modell ersetzen (siehe Tabelle 1).
| Ära | Definition von „Infrastruktur“ | Wo die Differenzierung lag |
|---|---|---|
| 1996 | Hardware | Betriebssystem + Anwendung |
| 2006 | Betriebssystem | Applikationsserver + Geschäftslogik |
| 2016 | Betriebssystem + Server | Cloud-Services + Microservices |
| 2026 | Cloud + Agentic AI |
Orchestrierung + Domänenwissen + Daten |
Dass Cloud-Infrastruktur in Tabelle 1 als „Infrastruktur“ erscheint, bedeutet nicht, dass sie Stand heute an Bedeutung verloren hat – im Gegenteil. Für den Betrieb von KI-Infrastruktur ist die Cloud sogar unverzichtbar. LLM-Inferenz erfordert spezialisierte Hardware, die sich nur wenige Unternehmen in großen Stückzahlen selbst anschaffen. Der Ressourcenbedarf von Agenten kann stark schwanken – von massiver Rechenleistung für wenige Sekunden bis hin zu Phasen völliger Inaktivität. Nur ein elastisches, nutzungsbasiertes Modell ist hier wirtschaftlich sinnvoll. Und wenn Agenten parallel arbeiten, andere Agenten koordinieren und Hunderte externe API-Aufrufe gleichzeitig ausführen, ist Skalierbarkeit keine Option, sondern Voraussetzung. Cloud wird also nicht unwichtig – sie wird vorausgesetzt. Genau wie Hardware 1996 nicht unwichtig war, sondern nur kein Differenzierungsmerkmal mehr.
Dieses Muster hat eine wichtige Implikation: Wer heute versteht, wo die Grenze gerade verläuft, kann ableiten, wohin sie sich als Nächstes verschieben wird.
Die neue Frage: Was ist der Kern meiner Anwendung?
Heute stellt sich niemand mehr die Frage „Was ist ein Betriebssystem?“ Aber die gleiche Grundfrage – „Was ist eigentlich die Plattform, auf der ich aufbaue – und womit schaffe ich den eigentlichen Mehrwert?“ – stellt sich auf einer neuen Ebene. SaaS-Anbieter fragen sich beispielsweise: Was ist eigentlich der Kern meiner Anwendung, wenn Kunden zunehmend erwarten, dass ein KI-Agent ihre Geschäftsprozesse versteht und automatisiert? Softwareentwickler fragen sich: Was ist der Kern meiner Anwendung, wenn ein Large Language Model (LLM) den Großteil der Geschäftslogik übernehmen kann? Architekten fragen sich: Wo endet mein Code und wo beginnt der Agent oder der Prompt?
Diese Fragen sind nicht abstrakt. Sie verändern nicht nur die Art, wie Software gebaut, deployt und betrieben wird – sie beeinflussen inzwischen sogar, wie Softwareunternehmen an der Börse bewertet werden. Wenn ein LLM die Kernfunktionalität eines SaaS-Produkts in wenigen Wochen replizieren kann, dann steht nicht weniger auf dem Spiel als das Geschäftsmodell ganzer Branchen. Die Frage „Was ist der Kern meiner Anwendung?“ ist damit keine technische Frage mehr – sie ist eine existenzielle. Und die Antwort verschiebt sich gerade fundamental: weg vom Code, weg von Features, hin zu Domänenwissen, proprietären Daten und der Fähigkeit, KI-gestützte Systeme intelligent zu orchestrieren.
Von CORBA-Objekten über Microservices zu KI-Agenten
Die Parallele ist frappierend. In den 2010er-Jahren wurden etliche monolithische Anwendungen in Microservices zerlegt – kleine, unabhängig deploybare Einheiten mit klar definierten Schnittstellen. Heute erleben wir eine ähnliche Transformation: Microservices werden durch KI-Agenten erweitert und teilweise ersetzt. Agenten sind autonome Softwareeinheiten, die ein Ziel verfolgen, eigenständig Entscheidungen treffen und über definierte Schnittstellen mit ihrer Umgebung interagieren.
Die Architekturmuster wiederholen sich – nur die Abstraktionsebene steigt (siehe Tabelle 2).
| Konzept | 1996: CORBA | Microservice | 2026: KI-Agent |
|---|---|---|---|
| Einheit | CORBA-Objekt | Microservice | KI-Agent |
| Vermittlung | Object Request Broker | API Gateway | Agent Runtime |
| Schnittstellendefinition | IDL | OpenAPI | Schemas/MCP |
| Plattformdienste | CORBAservices | Cloud Services | Foundation Models, Guardrails |
| Entwicklungsframework | C++/Java-Frameworks | Spring Boot, Express | Agent SDK |
| Auffinden von Diensten | CORBA Naming Service | Service Discovery | Agent Registry |
Tabelle 2 zeigt: Die Probleme, die 1996 mit CORBA gelöst werden sollten – Verteilung, Schnittstellendefinition, Service Discovery, Plattformdienste – sind die gleichen Probleme, die heute mit KI-Agenten adressiert werden. Nur auf einer höheren Abstraktionsebene. Dabei ist über die Jahre hinweg immer mehr von dem, was einst als „Glue Code“ manuell implementiert werden musste, in Abstraktionsschichten gewandert – von IDL-Stubs über API-Gateways bis hin zum LLM, das eine Integrationsarchitektur heute allein über ein entsprechendes agentenbasiertes KI-Muster realisieren kann.
Exkurs Infrastruktur für Agenten: Modellkataloge, Laufzeitumgebungen und Werkzeuge
Viele Unternehmen haben in den letzten Jahren umfassende KI-Infrastrukturen aufgebaut. Zusammen bilden sie eine vollständige Plattform für die Entwicklung, Bereitstellung und den Betrieb von KI-Agenten – und orientieren sich dabei an den Blaupausen, die aus der Microservices-Welt bekannt sind.
Modellkatalog: Den Grundstein vieler KI-Anwendungsarchitekturen bildet ein (intern oder extern verfügbarer) Modellkatalog. Dieser bietet Zugang zu KI-Modellen verschiedener Anbieter, ergänzt um Guardrails für verantwortungsvolle KI-Nutzung sowie Wissensdatenbanken für unternehmensspezifische Datenquellen – und abstrahiert so die Komplexität der Modellauswahl und des Modellbetriebs. AWS bietet hier beispielsweise Amazon Bedrock an – einen vollständig verwalteten Service, der Zugang zu über 100 Grundlagenmodellen von Anbietern wie Anthropic, Meta, Mistral und Amazon selbst bereitstellt. Es gibt aber auch zahlreiche andere Modellkataloge wie den von Hugging Face oder auch unternehmensinterne Implementierungen.
Agenten-basierte Laufzeitumgebungen: Relativ neu sind dedizierte Laufzeitumgebungen für Agenten. Analog zu Container-Diensten der Cloud übernehmen diese Bereitstellung, Skalierung, Überwachung, Speicher- und Kontextverwaltung sowie die Orchestrierung externer Zugriffe. Entwickler können sich so auf die Fachlichkeit konzentrieren, während die Laufzeitumgebung den Betrieb übernimmt. „Amazon Bedrock AgentCore“ (siehe Abb. 2) ist beispielsweise die Laufzeitumgebung für Agenten von AWS und bietet eine vollständig verwaltete Infrastruktur, die entsprechend skaliert und sich mit typischen Komponenten eines KI-Ökosystems integrieren lässt. Agenten lassen sich auch auf Kubernetes betreiben, allerdings müssen dann Sicherheit, Skalierung und Kapazitätsplanung selbst gelöst werden – bei hohem Aufwand und geringer Wertschöpfung.
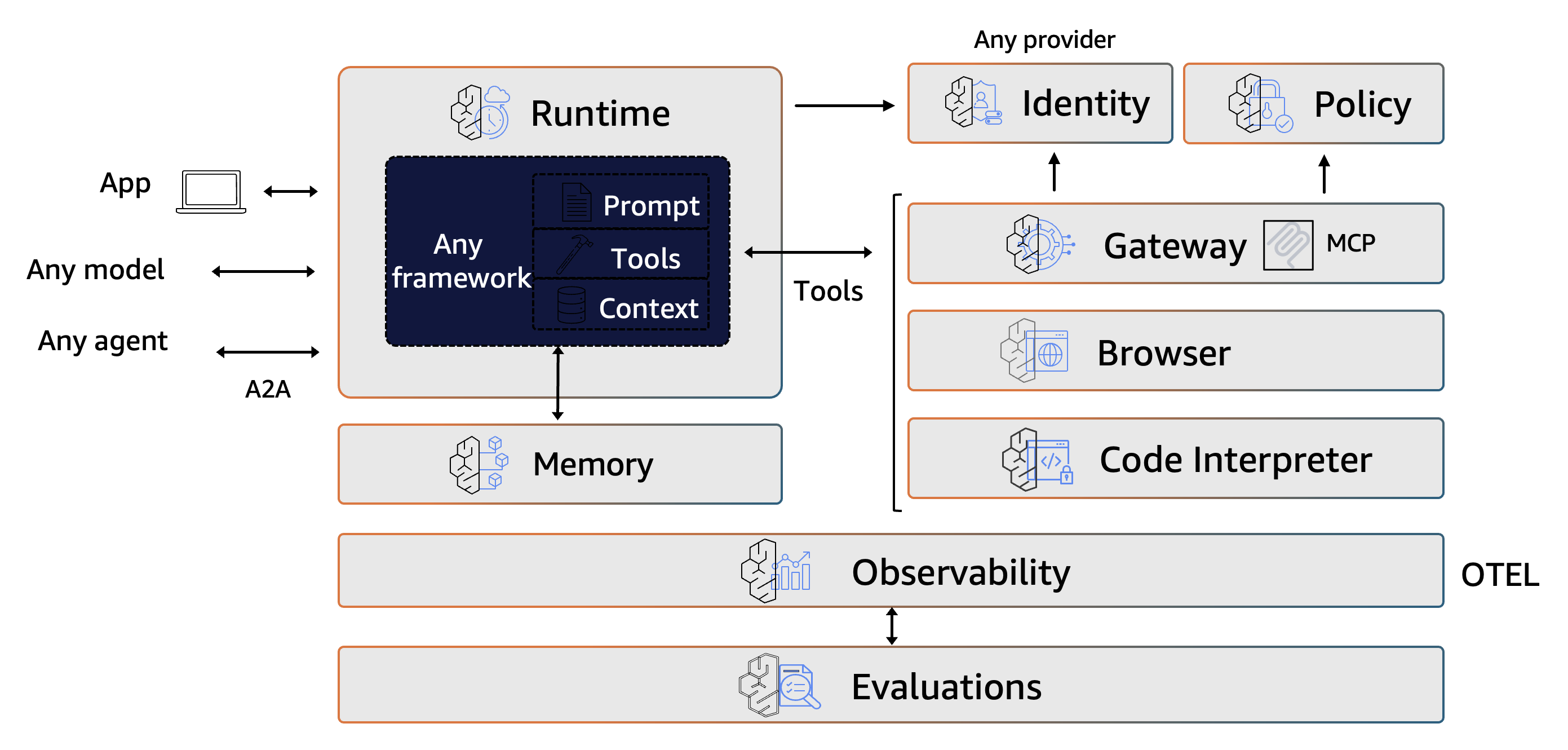
Abb. 2: Plattform Amazon Bedrock AgentCore
Agenten-basierte SDKs: Für die Entwicklung von Agenten stehen in der Regel Open-Source-basierte Entwicklungsframeworks zur Verfügung. Vergleichbar mit der Rolle von Spring Boot für Microservices unterscheiden sich diese Frameworks je nach Herkunft in ihrem Ansatz. Das Strands Agents SDK beispielsweise verfolgt einen modellgetriebenen Ansatz: Agenten werden deklarativ über ihre Ziele, verfügbaren APIs und Verhaltensregeln definiert. Das SDK übernimmt die Orchestrierung der Interaktion zwischen Agenten, LLMs und APIs. Strands startete als Python-Framework und wird inzwischen für weitere Sprachen verfügbar gemacht. Als Open-Source-Projekt steht es dabei bewusst in der Tradition, die auch Java großgemacht hat: offene Standards, Community-getrieben und herstellerunabhängig einsetzbar.
Agenten-basierte Werkzeuge: KI verändert nicht nur, wie Software betrieben wird, sondern auch, wie sie entsteht. Programmcode-generierende Agenten sind entweder in einer integrierten Entwicklungsumgebung eingebettet oder arbeiten direkt im Terminal und haben von dort Zugriff auf andere Agenten sowie Quellcode-Bibliotheken. Auch hier ist zu beobachten, wie sehr sich die Schnittstelle zwischen Entwickler und Werkzeug in den vergangenen Jahrzehnten verändert hat. Mit Kiro beispielsweise tritt eine KI-gestützte Entwicklungsumgebung an, die den Entwicklungsprozess selbst durch Agenten transformiert.
Kiro verfolgt dabei den Ansatz der „Spezifikations-getriebenen Entwicklung“ (siehe Abb. 3). Ausgehend von einer Anforderung generiert ein Agent zunächst eine Spezifikation – mit User-Storys, Akzeptanzkriterien und technischem Design. Das Team iteriert, bis die Spezifikation steht. Erst dann übernimmt ein Agent die Implementierung und schreibt Tests auf Basis der definierten Kriterien. Auch als Terminal-Variante verfügbar, bringt Kiro Agenten direkt dorthin, wo Entwickler arbeiten – mit Zugriff auf Laufzeitumgebungen, Konfiguration und Log-Dateien.

Abb. 3: Spezifikations-getriebene Entwicklung mit Kiro
Auch hier zeigt sich das diskutierte Muster: Was gestern Innovation war, wird zur Selbstverständlichkeit. Das Schreiben von Spezifikationen, das Übersetzen von Anforderungen in Code wird automatisiert und von einem Agenten übernommen. Die Wertschöpfung des Entwicklers verschiebt sich: weg vom Schreiben von Code, hin zur Definition von Anforderungen und dem Bewerten von Ergebnissen.
Von syntaktischer zu semantischer Entkopplung
Die Geschichte der Softwarearchitektur ist – vor allem im Kontext einer unternehmensweiten Architektur – auch eine Geschichte der Entkopplung. Enterprise Java Beans, CORBA, Webservices, Microservices – all diese Ansätze hatten auch das Ziel, Softwarekomponenten unabhängiger voneinander zu machen. Doch jeder dieser Ansätze hatte eine gemeinsame Voraussetzung: Beide Seiten mussten sich auf ein exaktes, formales Schema einigen. IDL bei CORBA, WSDL bei SOAP, OpenAPI bei REST. Änderte sich das Schema, brach die Integration. Dafür brauchte es Middleware – Enterprise-Service-Busse, API-Gateways, Integrationsplattformen – die diese formalen Verträge durchsetzte und vermittelte (siehe Tabelle 3).
| Ära | Entkopplungsmechanismus | Schwachstelle |
|---|---|---|
| 1990er | IDL/CORBA |
Enge Kopplung an ORB und IDL-Compiler |
| 2000er | WSDL/SOAP/ESB |
XML-Komplexität, schwere Middleware |
| 2010er | REST/OpenAPI/JSON | Schema-Bruch = Ausfall |
| 2020er | GraphQL/gRPC/Protobuf |
Flexibler, aber formale Contracts bleiben Pflicht |
| 2026+ | LLM + MCP/Tool Schemas |
Semantisches Verständnis, fehlertolerante Interpretation |
Ein LLM kann ein JSON-Dokument interpretieren, auch wenn sich Feldnamen geändert haben, eine API-Dokumentation lesen und den Aufruf selbst konstruieren oder zwischen Formaten übersetzen – ohne expliziten Konverter. Die Entkopplung verschiebt sich von der syntaktischen Ebene (exaktes Format) auf die semantische Ebene (Bedeutung). Die Middleware wird durch semantisches Verständnis erweitert.
Das Model Context Protocol (MCP) steht an der Schnittstelle dieser beiden Welten. Es definiert, wie Agenten mit externen APIs und Datenquellen interagieren – welche Operationen verfügbar sind, welche Parameter erwartet werden, welche Ergebnisse zurückgeliefert werden. MCP ist, wenn man so will, die IDL der Agenten-Ära. Aber anders als IDL ist MCP darauf ausgelegt, von einem LLM interpretiert zu werden – nicht von einem Compiler. Das macht die Integration fehlertoleranter und adaptiver als jede formale Schnittstellendefinition zuvor.
Java und die Frage der Programmiersprache
An dieser Stelle drängt sich die Frage auf, welche Rolle Java in dieser neuen Welt spielt? Die dominanten Agenten-Frameworks – Strands, LangChain, CrewAI – sind Python-basiert. Die LLM-Ökosysteme rund um Hugging Face und PyTorch ebenso. Hat Java in der Agenten-Ära ausgedient?
Die Antwort liegt im Muster der aufsteigenden Infrastrukturgrenze. Java ist heute die Sprache, in der ein Großteil der Unternehmensinfrastruktur (Microservices, APIs, Cloud-Plattformen) geschrieben ist. Amazon Bedrock, AgentCore, und auch wesentliche Teile der AWS-internen Infrastruktur selbst – vieles davon läuft auf der JVM. Wenn Agenten über MCP mit Tools interagieren, dann rufen sie in vielen Fällen Java-basierte Services auf. Auch wenn Java-Frameworks wie Spring AI oder Quarkus mit LangChain4j existieren, werden die Agenten selbst meist in Python geschrieben. Java ist jedoch die Infrastruktur, auf der Agenten operieren. Es ist exakt das gleiche Muster wie bei einem Betriebssystem: unsichtbar, aber unverzichtbar.
Darüber hinaus macht die semantische Entkopplung durch LLMs die Frage der Programmiersprache zunehmend irrelevant. Wenn ein Python-Agent über MCP einen Java-Service aufruft, der einen Rust-Service anspricht, dann ist die Implementierungssprache jeder Komponente ein Implementierungsdetail – so wie heute kaum jemand den Java-Bytecode betrachtet, der „unter der Haube“ generiert wird. Die Plattformunabhängigkeit, die Java 1996 auf Bytecode-Ebene versprach, wird in der Agenten-Ära auf Protokoll-Ebene eingelöst – wobei Protokolle wie MCP nicht nur syntaktische Schnittstellen definieren, sondern durch das LLM semantisch interpretiert werden. Die Programmiersprache wird zur Infrastruktur – und das semantische Protokoll zum neuen Bytecode.
Die Lektion aus 30 Jahren
Was lehren diese 30 Jahre? Drei Erkenntnisse stechen hervor.
Erstens: Die Architekturmuster sind beständiger als die Technologien. Verteilung, Komponentenorientierung, Plattformunabhängigkeit, standardisierte Schnittstellen – diese Prinzipien galten für CORBA, für Microservices und gelten für KI-Agenten. Wer die Muster versteht, kann Technologiewechsel besser meistern.
Zweitens: Die konkrete Technologie ist fast immer falsch vorhergesagt. Ich lag 1996 mit CORBA, Java Applets und OpenDoc daneben. Aber die Richtung stimmte. Das bedeutet heute: Welche KI-Modelle und Infrastrukturkomponenten sich durchsetzen werden, ist offen – aber die Richtung hin zu autonomen, KI-gestützten Softwareeinheiten als primärem Architekturmuster ist gesetzt.
Drittens: Was heute Differenzierungsmerkmal ist, wird morgen Infrastruktur. Dies ist ein klar zu erkennendes Muster der letzten 30 Jahre und könnte sich zu einer Art Naturgesetz der Softwareindustrie entwickeln.
Ein Blick auf 2056
In den kommenden 30 Jahren dürften sich selbst orchestrierende Agenten so selbstverständlich sein wie heute die Nutzung von Microservices aus der Cloud. Was genau wir dann als Infrastruktur wahrnehmen und womit Mehrwertleistungen erbracht werden, lässt sich heute nicht vorhersagen. Aber dass wir eine neue Definition von Infrastruktur haben werden, daran sollte nach der Entwicklung der letzten 30 Jahre kaum Zweifel bestehen.
1996 war die zentrale Frage technisch: Welches Betriebssystem? 2026 ist sie architektonisch: Was ist der Kern meiner Anwendung? Wenn sich das Muster der Infrastrukturverschiebung fortsetzt, wird sie 2056 vor allem kreativ zu beantworten sein: Nicht das „wie baue ich etwas“ wird entscheidend sein, sondern welchen Mehrwert kann ich liefern? Das „Wie“ wäre dann vollständig in die Infrastruktur gewandert – übrig bliebe nur noch das „Was“. Und vielleicht fragt dann jemand in einer Jubiläumsausgabe des JavaSPEKTRUM zum 60. Geburtstag: „Wenn alles, was ich mir vorstellen kann, auch gebaut werden kann – was sollte ich mir dann vorstellen?“
Quelle Aufmacherbild, AdobeStock









