

Manchmal hat man ein Problem, grübelt und grübelt und dann erzählt man es einem Kollegen (in meinem Fall Michael Jentsch, https://www.jentsch.io/), und der bringt einen nicht nur auf die richtige Spur, sondern eröffnet gleich komplett neue Welten.
Was aber, wenn das Video nicht bei YouTube ist? Hier half mir Michael weiter. Er empfahl mir das Open-Source-Tool Whisper [1]. Dabei handelt es sich um ein KI-Modell für Automatic Speech Recognition (ASR), das also genau zu diesem Zweck trainiert wurde.
Das Problem und die erste Lösung
Aber der Reihe nach – alles fing damit an, dass ich ein mittels Microsoft Teams geführtes Interview herunter tippen wollte, um es als Text zu veröffentlichen. Welch eine stupide Arbeit! Dabei dachte ich daran, wie schön es wäre, wenn ich beliebige Videos selbst transkribieren könnte, wie es beispielsweise YouTube seit einiger Zeit macht. Hier reicht es ja bekanntlich, unter „Einstellungen“ die Untertitel zu aktivieren, und schon kann ich mitlesen, was gesprochen wird (s. Abb. 1).
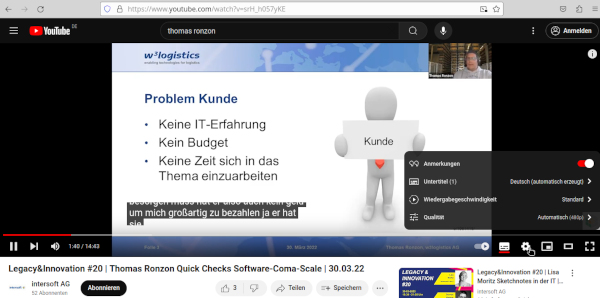
Abb. 1: Untertitel bei YouTube
Zwar kommt es genauso wie ChatGPT von OpenAI, im Gegensatz zu ChatGPT kann aber alles auf deinem eigenen Rechner laufen. Es ist also nicht notwendig, die Daten in die Cloud zu senden. Alle Zugriffe sind rein lokal und keine Daten werden beispielsweise an OpenAI zurückgesendet. Alles, was du tun musst, ist wie immer zunächst die Installation.
Die Installation
Da Whisper in Python geschrieben ist, ist zunächst einmal Python zu installieren. Hier solltest du darauf achten, dass du mindestens die Version 3.9 verwendest. Eine Installationsanleitung für Python findet sich hier [2]. Neben dem eigentlichen Interpreter python ist in der Distribution der eigene Paketmanager pip enthalten. Je nachdem, welche Version oder Versionen du installiert hast, kann er auch zum Beispiel pip3, pip3.11… heißen. Dieser lädt die benötigten Bibliotheken inklusive Abhängigkeiten automatisch herunter.
Da es aber in Python leider üblich ist, dass Versionen der Libraries nicht unbedingt miteinander kompatibel sind und dass bestimmte Libraries bestimmte Versionen anderer voraussetzen, solltest du dir erst mal eine eigene, private Umgebung für dein Projekt (in diesem Fall Whisper) anlegen. Folgendes legt die private Umgebung „whisperbastel“ an:
python3.11 -m venv whisperbastel
Das Aktivieren bedeutet, dass du nun mit dieser Umgebung arbeiten möchtest:
whisperbastel/bin/activate bzw. whisperbastel\Scripts\activate.bat
Nun kannst du endlich Whisper selbst installieren. Dies geht am einfachsten, wenn du direkt das Repository klonst:
pip3.11 install git https://github.com/openai/whisper.git
Jetzt installiert pip nicht nur Whisper, sondern auch alle Abhängigkeiten. Ob alles funktioniert hat, prüfst du am einfachsten durch den in Listing 1 gezeigten Aufruf.
whisper –-help
(base) ronzon@linux:~> whisper --help
usage: whisper [-h] [--model MODEL] [--model_dir MODEL_DIR]
[--device DEVICE]
[--output_dir OUTPUT_DIR]
[--output_format {txt,vtt,srt,tsv,json,all}]
[--verbose VERBOSE] [--task {transcribe,
translate}]
[--language {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,
de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,he,hi,hr,ht,hu,hy,
id,is,it,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,
mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,ro,ru,sa,sd,si,sk,
sl,sn,so,sq,sr,su,sv,sw,ta,te,tg,th,tk,tl,tr,tt,uk,ur,uz,vi,yi,
yo,yue,zh,Afrikaans,Albanian,Amharic,Arabic,Armenian,Assamese,
Azerbaijani,Bashkir,Basque,Belarusian,Bengali,Bosnian,Breton,
Bulgarian,Burmese,Cantonese,Castilian,Catalan,Chinese,Croatian,
Czech,Danish,Dutch,English,Estonian,Faroese,Finnish,Flemish,
French,Galician,Georgian,German,Greek,Gujarati,Haitian,
Haitian Creole,Hausa,Hawaiian,Hebrew,Hindi,Hungarian,Icelandic,
Indonesian,Italian,Japanese,Javanese,Kannada,Kazakh,Khmer,
Korean,Lao,Latin,Latvian,Letzeburgesch,Lingala,Lithuanian,
Luxembourgish,Macedonian,Malagasy,Malay,Malayalam,Maltese,
Mandarin,Maori,Marathi,Moldavian,Moldovan,Mongolian,Myanmar,
Nepali,Norwegian,Nynorsk,Occitan,Panjabi,Pashto,Persian,Polish,
Portuguese,Punjabi,Pushto,Romanian,Russian,Sanskrit,Serbian,
Shona,Sindhi,Sinhala,Sinhalese,Slovak,Slovenian,Somali,Spanish,
Sundanese,Swahili,Swedish,Tagalog,Tajik,Tamil,Tatar,Telugu,
Thai,Tibetan,Turkish,Turkmen,Ukrainian,Urdu,Uzbek,Valencian,
Vietnamese,Welsh,Yiddish,Yoruba}]
[--temperature TEMPERATURE] [--best_of BEST_OF]
[--beam_size BEAM_SIZE] [--patience PATIENCE]
[--length_penalty LENGTH_PENALTY]
[--suppress_tokens SUPPRESS_TOKENS]
[--initial_prompt INITIAL_PROMPT]
[--condition_on_previous_text CONDITION_ON_PREVIOUS_
TEXT]
[--fp16 FP16]
[--temperature_increment_on_fallback TEMPERATURE_INCREMENT_
ON_FALLBACK]
[--compression_ratio_threshold COMPRESSION_RATIO_THRESHOLD]
[--logprob_threshold LOGPROB_THRESHOLD]
[--no_speech_threshold NO_SPEECH_THRESHOLD]
[--word_timestamps WORD_TIMESTAMPS]
[--prepend_punctuations PREPEND_PUNCTUATIONS]
[--append_punctuations APPEND_PUNCTUATIONS]
[--highlight_words HIGHLIGHT_WORDS]
…Fertig! Ganz schön umfangreich die erste Hilfe, oder?
Die ersten Versuche
Nimm dir nun eine Videodatei. Achte aber darauf, dass das Videoformat auch unterstützt wird. Derzeit werden von Whisper folgende Formate unterstützt: mp3, mp4, mpweg, mpga, m4a, wav und webm [3].
Für meine ersten Tests nehme ich einen Beitrag des MDR zum 60-jährigen Jubiläum der Simson Schwalbe. Diesen kann man hier ansehen [4]. Ich habe ihn zunächst mittels Mediathekview [5] heruntergeladen und in eine mp4-Datei konvertiert. Warum ich genau mit diesem Video starte, erkläre ich später. Für deine Versuche kannst du aber auch jedes andere Video verwenden.
Möchte ich aus diesem Video den Text extrahieren, so genügt ein einfacher Aufruf:
whisper --model_dir ./models MDR_aktuell-Vor_60_Jahren__Simson_ präsentiert_die_Schwalbe-0526100956.mp4
Aber was ist das? Es dauert und dauert. Wenn das auch bei dir der Fall ist, solltest du einmal mit Betriebssystemmitteln nachsehen, wie ausgelastet deine CPU ist (s. Abb. 2).
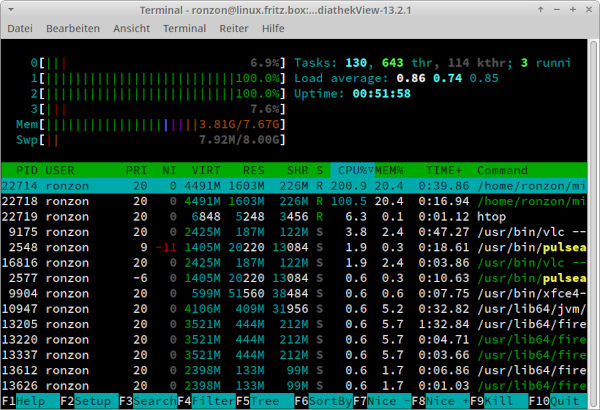
Abb. 2: Mehrere CPU-Kerne sind ausgelastet (ermittelt mittels htop)
Ist nämlich mindestens ein Kern der CPU zu 100 Prozent ausgelastet, so bedeutet dies, dass die Transkription auf der CPU ausgeführt wird. Aber genau das macht dies so langsam, da in diesem Fall die Unterstützung der GPU nicht verwendet wird (oder keine verbaut ist). Richtig „Dampf auf dem Kessel“ wirst du aber erst bekommen, wenn du diese aktivierst, indem du zum Beispiel die richtigen Treiber installierst (aber dies ist ein anderes Thema). Beim ersten Start wird nun zunächst versucht, ein Sprachmodell herunterzuladen. Per default wird das Modell „small“ verwendet. Derzeit werden die in Tabelle 1 gezeigten Modellgrößen angeboten.
| Modell | Anzahl Parameter (in Millionen) |
|---|---|
| tiny | 39 |
| base | 74 |
| small | 244 |
| medium | 769 |
| large | 1550 |
| large-v2 | 1550 |
Kurze Funktionsweise
Startest du Whisper ohne Sprachparameter, wird als Erstes die Sprache ermittelt, indem die ersten 30 Sekunden des Videos analysiert werden. Dies solltest du unbedingt beachten, wenn im Video die Sprache wechselt (siehe Tipps weiter unten). Danach beginnt die eigentliche Transkription, die du auch auf stdout mitverfolgen kannst.
Ist die Transkription fertig, so findest du neben deinem Video verschiedene Dateien. Da ist zum einen die klassische *.txt-Datei, die die pure Transkription beinhaltet. Alle anderen Dateien enthalten neben der Transkription auch Metadaten wie die Zeitangaben im Video.
Und? Was hat uns Whisper zu sagen?
Öffne einmal die *.txt Datei und du wirst erstaunt sein, wie gut diese Transkription ist. Du wirst aber auch feststellen, dass manche Sachen nicht richtig erkannt wurden. Hier ein Beispiel:
Die neue E-Schwalbe wird jedoch nicht wie ursprünglich geplant in Sul gebaut, sondern in Preislau, in Polen.
Gut, „Suhl“ ohne „h“ kann man noch als Rechtschreibfehler durchgehen lassen. Gleiches gilt für „Preislau“, das wohl „Breslau“ heißen soll. Trotzdem ist das Ergebnis erstaunlich gut.
Noch bessere Ergebnisse erhält man, indem man ein größeres Modell wählt. So nutzt der Aufruf:
whisper --model_dir ./models –model medium MDR_aktuell-Vor_60_Jahren__Simson_präsentiert_die_ Schwalbe-0526100956.mp4
das „medium“-Modell, das Whisper vor der ersten Verwendung des Modells auch einmal herunterlädt.
Aber alles hat seinen Preis. So ist die Laufzeit der Transkription umso länger, je größer das Modell ist. OpenAI gibt hier als Faustformel an, dass das „tiny“-Modell etwa 32-mal so schnell wie das „large“-Modell ist [6].
Anwendungsgebiete im Projektgeschäft
Nun beschäftigt sich die Tool-Talk-Kolumne ja per Definition mit „Tools für Architekten und Entwickler“. Wie also kann uns hier Whisper helfen?
Requirements-Engineering einmal anders
In Zeiten von Videokonferenzen habe ich einige Interviews mit den Anwendern per Videokonferenz durchgeführt. Dabei ist die Aufzeichnung sehr hilfreich, da man im Video noch einmal nachsehen kann, was der Anwender zu diesem oder jenen Thema gesagt hat. Achtung: Dass ihr die Erlaubnis der beteiligten Personen einholt, sollte selbstverständlich sein!
Wenn man nun aber das Video transkribiert, so kann man in den Aussagen sogar suchen!
Weiterbildung zum Nachschlagen
Gleiches gilt auch für Schulungsvideos oder Videos von Konferenzen. Einmal transkribiert und ich kann auch in diesen suchen. Ach ja – Podcasts als mp3 eignen sich ja genauso – schließlich werden auch mp3-Dateien unterstützt.
Übersetzungen
Stell dir vor, du findest ein Video auf Dänisch – kannst aber kein Dänisch. Warum transkribierst du es nicht und lässt es nachher automatisch übersetzen? Die Übersetzung kannst du dir ja dann sogar wieder vorlesen lassen. Quasi wie ein Babelfisch.
Lieder und Filmsuche
Auch im privaten Umfeld kann die Transkription hilfreich sein, indem du zum Beispiel deine Musik oder Videos transkribierst, um mp3s nicht anhand von ID-3-Tags (die eh niemand pflegt), sondern anhand von Fragmenten aus dem Lied zu finden. Ich bin mir sicher, du wirst hier auch noch einige Einsatzbereiche finden.
Tipp: Schau mal in die Tool-Talk vom JavaSPEKTRUM 2/24, https://www.sigs.de/artikel/lucene-einfuehrung-betrieb-tipps/ [7]. Hier habe ich den Einsatz der Suchmaschine Lucene beschrieben, mit der du natürlich alle Transkriptionen indizieren kannst, sodass die Suche ein Kinderspiel ist.
Aber wir komme ich an die Videos?
Das ist eigentlich immer das größte Problem. Sicher, je nach Version der Videokonferenzsoftware kann man das Video einfach herunterladen. Aber das ist ja nicht immer der Fall. Wir brauchen das Video nämlich gar nicht herunterzuladen. Warum? Ganz einfach – uns reicht doch die Tonspur. Sicher – es ist ein wenig umständlich, aber diese können wir quasi intern „aufnehmen“ und dann einfach weiter verwenden.
Möglich macht dies ein einfacher Soundeditor. Ich nehme hier gerne Audacity [8]. Der Grund ist ganz einfach. Das Tool ist nicht nur frei, sondern auch für die verschiedensten Betriebssysteme (auch ohne Installation direkt vom USB-Stick zu starten) erhältlich. Hier [9] findest du eine Anleitung, wie du den Ton mitschneiden kannst.
Tipp: Das klappt natürlich nicht nur mit Videos, sondern mit allem, was über die Soundkarte wiedergegeben wird. Ein Schelm, wer hier an Spotify denkt!
Was ist, wenn die Videos in einem Format vorliegen, das Whisper nicht unterstützt?
Hier muss das Video zunächst in ein von Whisper unterstütztes Format konvertiert werden. Bekannt ist sicherlich vlc [10], da er so ziemlich jedes Videoformat unterstützt. Schön, dass das Konvertieren hier [11] beschrieben ist (s. Abb. 3).
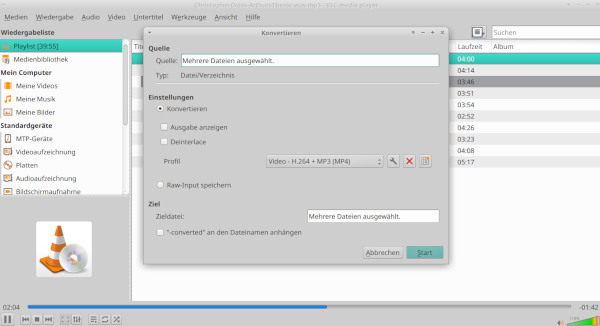
Abb. 3: vlc als Konverter
Möchte man allerdings viele Dateien im Batch konvertieren, so nutze ich hier gerne ffmpeg [12], bei dem es sich um ein echtes „Schweizer Messer“ für derartige Konvertierungen handelt. Schau mal in Listing 2.
#!/bin/sh
for file in "$@" ; do
name=`echo "$file" | sed -e "s/.mp4$//g"`
ffmpeg -i "$file" -ac 2 -f wav - | lame -b320
--preset standard - "$name.mp3"
doneMittels dieses kleinen Skripts kannst du alle *.mp4-Videos auf einen Rutsch in mp3-Dateien umwandeln.
Tipps und Wissenswertes aus der Praxis
Hier noch ein paar Tipps aus der Praxis und Dinge, die mir aufgefallen sind.
mp3s mit höherer Geschwindigkeit
Wird auch das Transkribieren beschleunigt, wenn man das mp3 beschleunigt, sodass es mit schnellerer Geschwindigkeit abgespielt wird? Ich jedenfalls bin genau auf diese Idee hereingefallen. Dem ist natürlich nicht so! So habe ich einmal Versuche durchgeführt, ein Stück mit ca. 2 Minuten Dauer mit 1,25-facher Geschwindigkeit zu transkribieren. Alles, was passierte, war, dass es ca. 1 Sekunde schneller transkribiert war, aber in sehr schlechter Qualität.
Trotzdem, einen Trick gibt es! Wenn ich etwa das Video nicht direkt herunterladen kann, sondern mit zum Beispiel Audacity aufzeichnen muss (siehe oben). So kann ich das Video beschleunigt wiedergeben und danach mit Audacity wieder in die ursprüngliche Geschwindigkeit übertragen. Je nach Länge des Videos lässt sich hier Zeit sparen. Nach meinen Erfahrungen liefern hier Geschwindigkeiten von bis zu 2-facher Originalgeschwindigkeit gute Werte.
Transkribieren von Musik
Bei meinen Versuchen mit Whisper habe ich verschiedene Quellen verwendet. Besonders interessante Effekte bekam ich, als ich versuchte, eine alte Schallplatte zu transkribieren, die ich vorher eingelesen hatte. Dabei handelte es sich um die Schallplatte „Schlagerauslese 1965“, die einige Besonderheiten aufwies, die auch bei anderen Quellen passieren können und deshalb hier noch einmal besprochen werden sollen.

Abb. 4: Rückseite der LP „Schlagerauslese 1965“
Sprachwechsel
Ein interessantes Phänomen ist, dass Whisper anscheinend gar keine Probleme damit hat, ob ein Text gesprochen ist oder gesungen wird. Die Texte auf der Schallplatte wurden jedenfalls sehr gut erkannt. Allerdings sind auf dieser Schallplatte deutsche und englische Lieder direkt hintereinander!
Probleme gab es auch, wenn im Text einer Sprache Wörter einer anderen Sprache auftauchten, die Whisper hier anscheinend nicht erwartet hatte. Hier ein Beispiel:
[04:23.000 --> 04:27.000] Denn sonst heiratet vom Fleck ein anderes Gönn in Deck
In Wirklichkeit heißt es im Liedtext nämlich „Denn sonst heiratet vom Fleck ein anderes Girl ihn weg!“.
Halluzinieren bei Lücken
Interessant ist auch, was passiert, wenn auf einer Schallplatte eine Pause zwischen zwei Musikstücken ist. Hier halluzinierte Whisper, indem es einfach die letzten Sätze stumpf wiederholte:
[04:50.000 --> 04:55.000] Schick der Rosen dann und wann, sprich nicht drüber
[04:55.000 --> 05:00.000] Wenn er's sehr gut küssen kann, sprich nicht drüber
[05:00.000 --> 05:05.000] Denn sonst heiratet vom Fleck ein anderes Gönn in
Deck
[05:05.000 --> 05:12.000] Sprich nicht drüber, sprich nicht drüber, sprich
nicht drüber
[05:25.000 --> 05:30.000] Wenn er's sehr gut küssen kann, sprich nicht drüber
[05:30.000 --> 05:35.000] Wenn er's sehr gut küssen kann, sprich nicht drüber...
[07:55.000 --> 07:59.000] Wenn er's sehr gut küssen kann, sprich nicht drüber
[07:59.000 --> 08:03.000] Wenn du träumst heute Abend
[08:03.000 --> 08:10.000] Du bist nicht allein, wenn du träumst von der Liebe
[08:10.000 --> 08:18.000] Es finden tausend junge Herzen heute keine Ruhe
Sprecherwechsel
Im Fall der LP kamen Wechsel des Interpreten vor, die werden von Whisper nicht erkannt beziehungsweise nicht speziell ausgewiesen! Dies ist natürlich umso wichtiger, wenn es für die spätere Verwendung von Belang ist, zu wissen, wer etwas gesagt hat. Schön ist allerdings, dass man in diesem Fall durch die Zeitangabe in der Ausgabe noch einmal im Video „nachschlagen“ kann. Behalte also das Original!
Allgemeine Tipps: Zerlegen von mp3-Dateien
Möchte man das Video nicht an einem Stück transkribieren, etwa weil es zu lange dauert, gibt es auch einen einfachen Trick. Zunächst wandelt man das Video in eine mp3-Datei um. Anschließend kann das Video durch stumpfes Teilen der Datei in handliche Happen geteilt werden. Das geht, da es sich bei mp3 um ein Streaming-Format handelt, ein Aufsetzen also jederzeit möglich ist.
Beachten sollte man jedoch, dass einzelne Worte verloren gehen können, da es ja sein kann, dass man mittendrin teilt. So teilt:
split -b 50MB MeinMP3.mp3
die Datei MeinMP3.mp3 in 50 MByte große „Happen“ auf, die dann deutlich leichter verarbeitet werden können. Das Zusammenführen kann dann wie üblich erfolgen:
cat Datei1.txt Datei2.txt Datei3.txt > FertigeTranskription.txt
Fazit
Es ist wirklich erstaunlich, wie einfach mit hoher Qualität Videos transkribiert werden können. Selbst wenn man diese noch einmal „Korrektur“ lesen muss, so sind die Einsatzgebiete im Projektalltag mannigfaltig. Sei es beim Schreiben von Spezifikationen, als Hilfe bei Besprechungsberichten oder als Hilfe bei fremden Sprachen. Probiere es einfach mal aus!
Weitere Informationen
[1] https://openai.com/index/whisper/
[2] https://www.ionos.com/digitalguide/websites/web-development/install-python/
[3] https://learn.microsoft.com/de-de/azure/ai-services/speech-service/whisper-overview
[4] https://www.mdr.de/video/mdr-videos/c/video-794876.html
[6] https://github.com/openai/whisper
[7] T. Ronzon, Tool Talk, in: JavaSPEKTRUM, 2/24, s. a.:
https://www.sigs.de/artikel/lucene-einfuehrung-betrieb-tipps/
[8] https://www.audacityteam.org/
[9] https://www.computerbild.de/artikel/cb-Tipps-Software-Audacity-PC-Sound-aufnehmen-31484611.html
[10] https://www.videolan.org/
[11] https://www.netzwelt.de/tipps/632-videodateien-vlc-player-konvertieren.html
[12] https://ffmpeg.org/








