Testautomatisierung gilt als Rückgrat moderner Softwareentwicklung. Jeder will sie – und doch scheitern erstaunlich viele Unternehmen an der Umsetzung. Nach über sieben Jahren in der Testautomatisierung und im Testmanagement – in Kundenprojekten von der Energiewirtschaft über die öffentliche Verwaltung bis hin zu SAP-Rollouts – hat sich ein Muster herauskristallisiert: Erfolg in der Testautomatisierung hängt weniger am gewählten Framework oder an der Anzahl automatisierter Testfälle. Er hängt an Einbettung in den Entwicklungsprozess, an passender Architektur und an Wartbarkeit. Fehlt einer dieser Faktoren, kippt die Suite – egal wie modern das Tooling ist. Die folgenden drei Projektbeispiele zeigen, was das in der Praxis bedeutet.
War Story: Wie eine Testsuite mit 1.000 Testfällen ihren Wert verlor
In einem Großprojekt wurde die Testautomatisierung komplett nach Südostasien ausgelagert. Die Idee: Ein Test Automation Manager koordiniert in Deutschland, ein Offshore-Team automatisiert. Die Scrum-Teams meldeten relevante User-Storys, der Automation Manager leitete sie weiter.
Das Offshore-Team automatisierte die Storys jedoch isoliert – ohne fachlichen Kontext, ohne bestehende Testfälle zu erweitern, ohne logische Ende-zu-Ende-Prozesse herzustellen. Da die Kolleginnen und Kollegen weder in den Sprint-Reviews noch in den Daily Stand-ups eingebunden waren, fehlte das Verständnis für fachliche Zusammenhänge. Die Kommunikationskette – Scrum-Team, Automation Manager, Offshore-Team – war schlicht zu lang: Wurde eine Story auf dem Weg nicht weitergegeben, blieb sie unberücksichtigt.
Der eigentliche Kipppunkt kam mit dem Personalwechsel: Als der erste Automation Manager das Projekt verließ, übernahm sein Nachfolger eine Suite mit rund 700 Testfällen, deren innere Logik er nicht kannte. Der Vorgänger hatte möglicherweise noch einen persönlichen Überblick – spätestens mit dem Wechsel war dieser unwiederbringlich verloren. Die Suite wuchs auf knapp 1.000 Testfälle, aber niemand konnte mehr beurteilen, welche Tests redundant waren, welche veraltete Funktionalitäten prüften und welche tatsächlich Mehrwert lieferten.
Die wöchentlichen Pipeline-Läufe lieferten Berichte mit Hunderten fehlgeschlagenen Tests – keine echten Bugs, sondern falsch-negative Ergebnisse: umbenannte Buttons, geänderte Workflows, veraltete Selektoren. Ein klassisches Flaky-Test-Problem, das jedoch nicht durch technische Maßnahmen wie intelligente Waits oder stabile Locators hätte gelöst werden können, sondern organisatorisch bedingt war. Die Analyse fiel zurück an die Tester in den Scrum-Teams. Sie mussten jeden Testfall einzeln öffnen, manuell nachtesten und abgleichen, ob ein echter Defekt vorlag oder die Automatisierung schlicht nicht mehr aktuell war.
Obwohl das Problem erkannt wurde, änderte sich nichts. Die Projektleitung sah keinen Anlass, den Prozess umzugestalten. Die Automatisierung wurde zum Feigenblatt – die Projektleitung konnte nach oben berichten „wir automatisieren“, während die Suite faktisch nur noch Mehraufwand erzeugte.
Was besser funktioniert: In anderen Projekten habe ich die Erfahrung gemacht, dass Testautomatisierung dann nachhaltig gelingt, wenn sie direkt in den Softwareentwicklungslebenszyklus eingebettet ist. Es lief immer dann am besten, wenn jedes Scrum-Team mindestens einen Tester mit Automatisierungskompetenz hatte, der Automatisierungsaufwand fest im Sprint eingeplant wurde und Testfälle Ende-zu-Ende gedacht und bei neuen Features erweitert statt isoliert neu erstellt wurden. Entscheidend war auch, dass sich die Tester teamübergreifend organisierten und ein gemeinsames Repository pflegten. So entstand eine Suite, die mit dem Produkt wuchs statt gegen es (siehe Abb. 1).
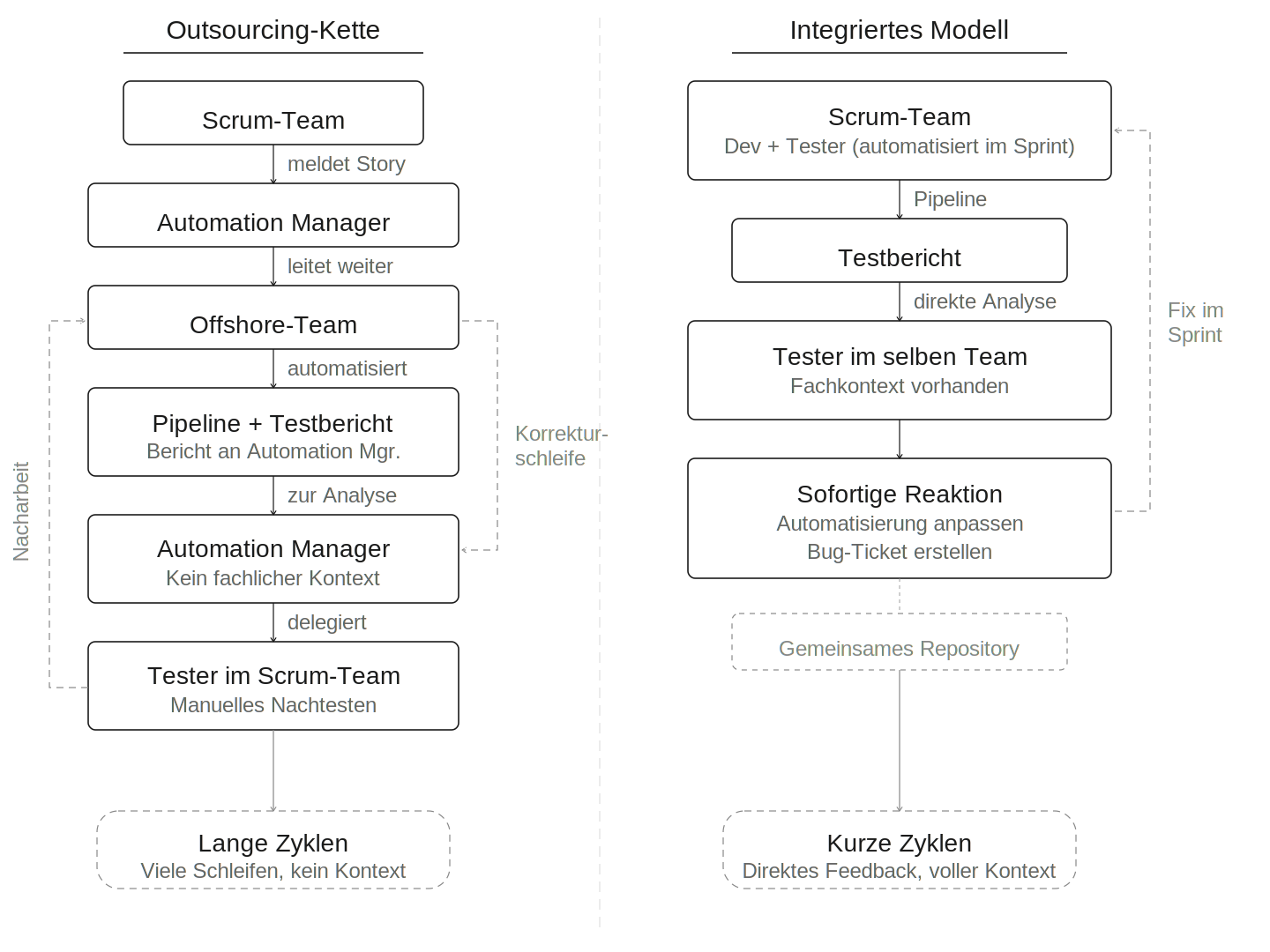
Abb. 1: Outsourcing-Kette vs. integriertes Modell
Architektur und Testdaten: Wann das Pattern Screenplay dem POM überlegen ist
In den meisten Projekten hat sich das Page Object Model (POM) bewährt: Seiten werden als Klassen modelliert, die Locators und Interaktionsmethoden kapseln. Für klassische Webanwendungen bleibt POM der pragmatische Standard.
In einem Projekt für die öffentliche Verwaltung stieß POM jedoch an seine Grenzen. Das Team entwickelte ein Berechtigungstool, das steuert, welche Nutzer auf welche Onlinedienste zugreifen dürfen. Das System arbeitete nicht mit klassischem Login, sondern mit zertifikatsbasierter Authentifizierung: Die Zertifikate lagen in einem Artifactory, das über spezifische Umgebungsvariablen und Zwei-Faktor-Authentifizierung abgesichert war – eine Architektur, die den Datenschutzanforderungen des Projekts geschuldet war. Diese mehrstufige Zugriffskonfiguration für verschiedene Zertifikatsprofile in jeder Page-Klasse redundant abzubilden, hätte mit POM zu erheblichem Wartungsaufwand geführt.
Das Screenplay Pattern löste dieses Problem elegant. Das Muster folgt dem Prinzip „Actors use Abilities to perform Interactions“ [1]. Jeder Actor wird einmalig mit seinen Fähigkeiten konfiguriert – in diesem Fall mit einem spezifischen Zertifikatsprofil und den daraus resultierenden Berechtigungen. Dieser Actor lässt sich dann in beliebig vielen Testszenarien wiederverwenden: etwa um zu prüfen, ob ein Nutzer ohne Berechtigung korrekterweise einen HTTP-403-Statuscode erhält. Das Pattern trennt sauber zwischen Akteuren, Fähigkeiten und Interaktionen, was die Wartbarkeit bei wachsender Rollenkomplexität deutlich verbessert [2].
Das Pattern Screenplay entfaltete seine Stärke auch beim Testdatenmanagement. Für bestimmte Testszenarien mussten Vorbedingungen hergestellt werden: Ein Nutzer mit der entsprechenden Berechtigung musste beispielsweise zunächst eine Gruppe anlegen, bevor ein anderer Testfall die Gruppenmitgliedschaft prüfen konnte. Statt diese Testdaten manuell über die Oberfläche zu erzeugen, erstellte der jeweilige Actor sie über die API (Application Programming Interface) – schneller, stabiler und unabhängig von Änderungen an der Benutzeroberfläche (UI). In Before-Methoden stellte der Actor über die Schnittstelle alle Vorbedingungen her, in After-Methoden räumte er auf. Das Pattern machte es dabei einfach, den richtigen Actor mit den richtigen Berechtigungen für die Testdatenerstellung einzusetzen.
Fairerweise: Screenplay ist kein Selbstläufer. Das Pattern bringt eine steilere Lernkurve mit als POM und erfordert ein Team, das bereit ist, sich auf ein abstrakteres Architekturmodell einzulassen. Für Projekte mit wenigen Rollen und einfacher Authentifizierung wäre der Aufwand kaum gerechtfertigt. Die Wahl bleibt eine Kontextentscheidung – aber genau das ist der Punkt: Architekturmuster sollten bewusst zum Projekt passen, nicht aus Gewohnheit übernommen werden.
Von der User-Story zum Testfall: KI-gestützte Workflows in der Praxis
KI verändert die Testautomatisierung an mehreren Stellen der Wertschöpfungskette. Entscheidend ist nicht der einzelne KI-Baustein, sondern die Verkettung zu einem durchgängigen Workflow. Mit dem Workflow-Tool n8n habe ich einen halbautomatisierten Prozess zur Testfallerstellung aufgebaut, der diesen Ansatz umsetzt.
Der Workflow beginnt mit einem Chatfenster in einer selbst gehosteten n8n-Instanz. Der Testmanager kopiert die User-Story hinein, ein Vorverarbeitungsschritt strukturiert die Eingabedaten – Titel, Beschreibung, Akzeptanzkriterien landen in separaten Feldern. Der KI-Agent arbeitet mit dem Modell o4-mini. Ursprünglich kam GPT-4o zum Einsatz, doch bei umfangreicheren Storys ging Kontext verloren und einzelne Akzeptanzkriterien wurden nicht abgedeckt. Für diesen spezifischen Anwendungsfall – die strukturierte Generierung von Testfällen aus komplexen Storys – erwies sich das kleinere Modell als konsistenter. Das Ergebnis hing dabei wesentlich vom Prompting, der Story-Struktur und dem Ausgabeschema ab. Jedes Modell hat seine Stärken, Schwächen und Kosten. Genau wie bei der Wahl zwischen POM und Screenplay-Pattern gilt auch hier: Es gibt keine universelle Lösung. Die Entscheidung muss zum konkreten Anwendungsfall passen.
Im Prompt steckt das Feintuning: Der Agent agiert in der Rolle eines erfahrenen QA-Analysten und kennt die Zielgruppe der Testfälle. Testschritte müssen im Imperativ formuliert sein, auf Deutsch und ohne Umlaute – wichtig für den späteren maschinellen Import. Jeder Testfall beginnt mit einem Kontextschritt. Fachliche Tests enthalten keine technischen Backend-Details, weil sie als Ende-zu-Ende-Abnahmetests über das Frontend konzipiert sind.
Die Ausgabe des Agenten liegt im JSON-Format (JavaScript Object Notation) vor, wird in einzelne Testfälle gesplittet und ins Xray-Importformat gemappt. Das Ergebnis ist eine CSV-Datei (Comma-Separated Values), die sich direkt über den Xray-Importer in Jira importieren lässt.
Bewusst ist der Workflow halbautomatisiert: Nicht jede Story ist relevant für einen Ende-zu-Ende-Test – diese Bewertung treffe ich als Testmanager selbst. Und vor dem Import prüfe ich die generierten Testfälle auf Vollständigkeit und Plausibilität. KI-Modelle können fehlerhafte oder unvollständige Ergebnisse liefern. Wer generierte Testfälle ungeprüft importiert, riskiert eine aufgeblähte Suite ohne Aussagekraft – einen Zustand, wie er im vorherigen Abschnitt am Outsourcing-Beispiel beschrieben wurde, nur mit anderem Verursacher.
Der Return on Investment (ROI) eines solchen Workflows lässt sich konkret beziffern. In einem Projekt lag der Aufwand für die manuelle Testfallerstellung je User-Story bei durchschnittlich 2,5 Stunden – inklusive Analyse der Akzeptanzkriterien, Formulierung mehrerer Testfälle und Eingabe ins Testmanagementsystem. Mit dem KI-Workflow reduzierte sich dieser Aufwand auf rund 30 Minuten Nacharbeit je Story: Prüfung, Nachjustierung und Import. Bei rund 140 User-Storys im Jahr ergibt sich eine Ersparnis von etwa 275 Stunden (siehe Abb. 2).
Diese Werte sind Erfahrungswerte aus einem spezifischen Projekt und lassen sich nicht ohne Weiteres verallgemeinern – die tatsächliche Ersparnis hängt von der Komplexität der Anforderungen, der Story-Struktur und der Projektorganisation ab. Was sich jedoch verallgemeinern lässt, ist der Effekt: Der einmalige Invest in den Aufbau eines Workflows – in diesem Fall rund acht Stunden – kann sich bereits nach wenigen User-Storys amortisieren, weil die manuelle Formulierung und Dokumentation von Testfällen weitgehend entfällt.
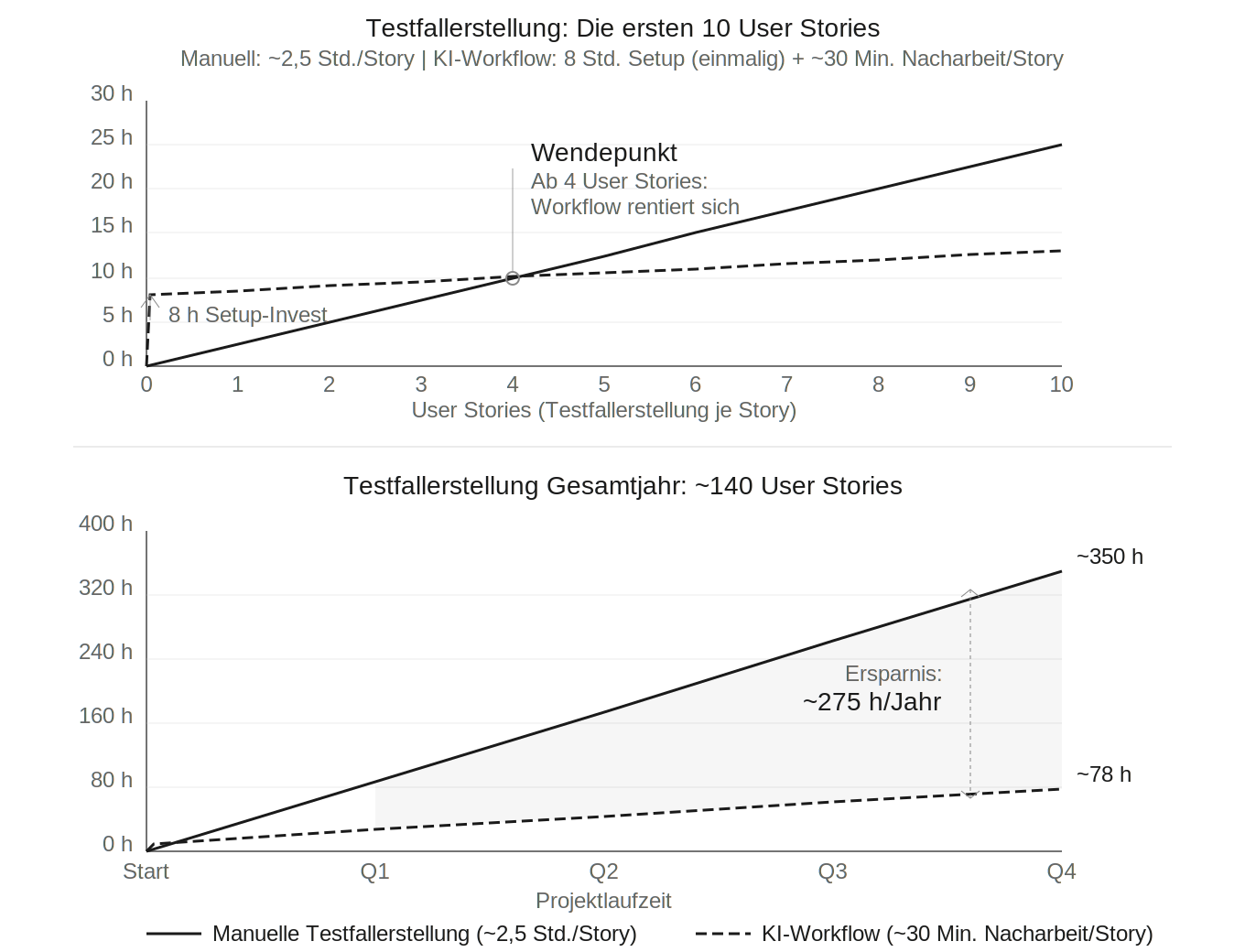
Abb. 2: Kumulativer Zeitaufwand Testfallerstellung – manuell vs. KI-Workflow
Im Atlassian Marketplace gibt es mittlerweile Alternativen wie den AI Test Case Generator [3], die KI-gestützte Testfallerstellung direkt in Jira integrieren. Der Vorteil eines eigenen Workflows liegt in der vollständigen Kontrolle über Prompt und Qualitätssicherung.
Ausblick: Was sich für Testteams ändert
Die Rolle des reinen Testautomatisierers wird sich verändern. KI-Agenten werden repetitive Arbeit zunehmend übernehmen – Gartner prognostiziert bis 2028 agentenbasierte KI in einem Drittel der Unternehmenssoftware [4]. Tester werden dadurch nicht überflüssig, aber ihre Aufgabe verschiebt sich: weniger Skripte schreiben, mehr Workflows konzipieren, Ergebnisse bewerten und Qualität verantworten.
Konkret bedeutet das für Teams, die heute Testautomatisierung betreiben: Wer KI einsetzt, muss dieselben Fragen beantworten wie bei jeder anderen Automatisierungsentscheidung auch. Passt das Werkzeug zum Kontext? Ist die Wartbarkeit gesichert? Gibt es fachliche Kontrolle? Die Technologie ändert sich, die Erfolgsfaktoren bleiben dieselben. Entscheidend ist nicht, wie viele Tests erzeugt werden können, sondern ob Teams verstehen, welche Tests relevant, wartbar und fachlich belastbar sind.
Literaturangaben
[1] A. Marcano, A. Palmer, J. Molak, J. F. Smart, Beyond Page Objects: Next Generation Test Automation with Serenity and the Screenplay Pattern, in: InfoQ, 2016, siehe: https://www.infoq.com/articles/Beyond-Page-Objects-Test-Automation-Serenity-Screenplay/
[2] J. Molak, Serenity/JS Handbook: Screenplay Pattern, siehe: serenity-js.org/handbook/design/screenplay-pattern
[3] Solidini, AI Test Case Generator for Jira, siehe: marketplace.atlassian.com/apps/1235008
[4] Gartner, Predicts 2025: Software Engineering, 19.11.2024, siehe: https://www.gartner.com/en/newsroom
Aufmacherbild per KI erstellt, ChatGPT